复杂度
大O复杂度关心的是:随着输入n的变化,算法的时间/空间占用变化的趋势。
因此会忽略常数,忽略低阶项。
比如:
O(2) O(500) O(10000)都写成O(1),表示常数级,不随n变化;
O(1000n)写成O(n),都是线性增长;
O(3n^2+10n+100)写成O(n^2);
数组
- 双指针
- 滑动窗口
- 固定窗口:双指针确定窗口大小
- 动态窗口:根据条件动态调整窗口
- 前缀信息
- 计算区间和:prefixSum[j] - prefixSum[i-1]
- 前缀积 / 后缀积:左右两侧累计信息组合
题目
27. 移除元素
双指针:fast遍历数组,slow记录不等于 val 的个数(位置)。
if (nums[fast] != val) { nums[slow++] = nums[fast]; }
581. 最短无序连续子数组
双指针:从两个方向遍历,找出中间无序数组的左右边界。
为什么左边界要从右往左比较min,而不是直接从左往右找第一个非升序位置?
126754389:从左往右找到的左边界是5,会漏掉局部升序的6 7
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| // 示例1 2 6 5 3 4 7 8
int max = Integer.MIN_VALUE;
int min = Integer.MAX_VALUE;
for (int i = 0; i < n; i++) {
// 从左向右,找中间子数组的右边界
if (nums[i] >= max) {// 对于升序数组,当前元素应大于之前的max
max = nums[i];// 正常更新max
} else {// 比当前max小的(说明非升序)都在中子数组范围内
end = i;
}
// 从右向左,找左边界
if (nums[n - 1 - i] <= min) {// 正常更新min
min = nums[n - 1 - i];
} else {
start = n - 1 - i;
}
}
|
76. 最小覆盖子串
滑动窗口:先统计t中各字符的频次,根据频次特征移动s的窗口
输入:s = “ADOBECODEBANC”, t = “ABC”
输出:“BANC”
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| public String minWindow(String s, String t) {
if (s == null || t == null || s.length() < t.length()) {
return "";
}
int[] need = new int[128];
for (char c : t.toCharArray()) {need[c]++;}
// 统计t中各字符的频次
int left = 0, right = 0;
int count = t.length(); // t总字符数
int start = 0, minLen = Integer.MAX_VALUE;
while (right < s.length()) {
char c = s.charAt(right);
if (need[c] > 0) {count--;}// 是t中的字符,计数--
need[c]--;// 对每个字符都执行,
// 因此即使下面d是无关的字符时,其need的值也不会大于0
right++;
while (count == 0) {// 满足条件,收缩窗口
if (right - left < minLen) {// 先记录开始位置和长度
minLen = right-left;
start = left;
}
// 收缩窗口
char d = s.charAt(left);
if (need[d] == 0) {count++;}// 刚好用到的字符,移出窗口则count需要++
need[d]++;
left++;
}
}
return minLen == Integer.MAX_VALUE ? "" : s.substring(start, start+minLen);
}
|
438. 找到字符串中所有字母异位词
固定长度滑动窗口:窗口长度固定为 p.length(),统计窗口内字符频次是否与 p 相同。
变长窗口:根据字符是否平衡调整窗口长度,如果窗口长度和 p 等长则加入left。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| # 定长
def findAnagrams(self, s, p):
n, m = len(s), len(p)
if n < m:
return []
need = [0] * 26
window = [0] * 26
for ch in p: # p中各字母个数
need[ord(ch) - ord('a')] += 1
ans = []
for index, ch in enumerate(s):
window[ord(ch) - ord('a')] += 1
if index >= m:# 移出窗口
out = s[index - m]
window[ord(out) - ord('a')] -= 1
if window == need:
ans.append(index - m + 1)
return ans
# 变长
def findAnagrams(self, s, p):
n, m = len(s), len(p)
if n < m:
return []
need = [0] * 26
for ch in p: # p中各字母个数
need[ord(ch) - ord('a')] += 1
ans = []
left=0
for right, ch in enumerate(s):
need[ord(ch) - ord('a')] -= 1
while need[ord(ch) - ord('a')]<0:
need[ord(s[left])-ord('a')] +=1
left += 1
if right-left+1 == m:
ans.append(left)
return ans
|
209. 长度最小的子数组
滑动窗口:right指针扩展窗口,left指针收缩窗口。
注意收缩使用while循环。
238. 除自身以外数组的乘积
前缀积 / 后缀积:answer[i] 等于 i 左侧所有元素乘积乘以 i 右侧所有元素乘积。
可以先从左到右写入前缀积,再从右到左用一个变量维护后缀积并乘到结果中。
15. 【三数之和】
排序+双指针:固定一个数,使用左右指针寻找另外两个数。
链表
19. 删除链表的倒数第N个节点
双指针:first先走n步,然后second和first一起走,直到first到达末尾。
160. 链表相交
双指针:pA,pB以不同顺序遍历两个链表,两指针相等时即为相交节点。
1
2
3
4
5
6
| ListNode pA = headA, pB = headB;
while (pA != pB) {
pA = pA == null ? headB : pA.next;
pB = pB == null ? headA : pB.next;
}
return pA;
|
142. 环形链表 II
双指针:快慢指针,fast每次走两步,slow每次走一步。
快慢指针相遇后,令另一个指针ptr从head开始每次走一步,其与slow相遇的节点即为环入口。
原理:设head到环入口距离为a,环入口到相遇点距离为b,相遇点到环入口距离为c。
则有:2(a+b) = a+b+n(b+c) => a = c + (n-1)(b+c),即head到环入口距离 = 相遇点到环入口距离加上若干个环的周长。
两倍慢指针路程 = 快指针路程
因此ptr与slow相遇的节点即为环入口。
206. 反转链表
使用三个指针:pre,cur,next。next保存cur的下一个节点,防止断链。
- 回文链表
使用快慢指针找到链表中点,原地反转后半部分链表(保证空间O(1)),然后比较前半部分和反转后的后半部分。
哈希表
哈希表:通过哈希函数将键映射到值。
常用操作:插入、删除、查找,平均时间复杂度为O(1)。
面向问题:元素是否出现过,或是否在集合里
题目
202. 快乐数
对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和,如果这个数最终变为1,那么这个数就是快乐数。也可能进入无限循环。
使用哈希表记录出现过的平方和,避免进入循环。
454. 四数相加 II
哈希表key为前两数组合的和,value为该和出现的次数。
对于后两数组合的和,查找哈希表中是否存在相反数。
1
2
3
4
5
| HashMap<Integer, Integer> map = new HashMap<>();
for (int i : A) for (int j : B) map.put(i + j, map.getOrDefault(i + j, 0) + 1);
int count = 0;
for (int i : C) for (int j : D) count += map.getOrDefault(-(i + j), 0);
return count;
|
字符串
Java中字符串不可变,修改字符串会创建新对象。
多使用StringBuilder进行字符串拼接。
题目
541. 反转字符串 II
每隔2k个字符反转前k个字符。
1
2
3
4
5
6
7
8
| for (int i = 0; i < ch.length; i += 2*k) {
int left = i, right = Math.min(i+k-1, ch.length-1);
while (left < right) {
char temp = ch[left];
ch[left++] = ch[right];
ch[right--] = temp;
}
}
|
151. 翻转字符串里的单词
去除多余空格,反转整个字符串,再反转每个单词。
1
2
3
4
5
6
| while (left <= right) {// left为整个串的开头位置,不移动
int end = right;
while (left <= right && s.charAt(right) != ' ') { right--; }
sb.append(s.substring(right+1, end+1)).append(" ");
while (left <= right && s.charAt(right) == ' ') { right--; }// 去空格
}
|
- 删除字符串中的所有相邻重复项
双指针,fast遍历输入串,slow维护结果串。
双指针其实可以理解为分别操作两个串,由于fast一定比slow快,因此可以复用相同空间。
1
2
3
4
5
6
7
8
9
10
11
| public String removeDuplicates(String s) {
char[] ch = s.toCharArray();
int fast = 0;
int slow = 0;
while(fast < s.length()){
if(slow > 0 && ch[fast] == ch[slow - 1]) { slow--; }// 当前slow位置未赋值,slow-1为结果串最后一个位置
else { ch[slow++] = ch[fast]; }
fast++;
}
return new String(ch,0,slow);
}
|
KMP算法
KMP算法:利用已经匹配过的信息,避免重复匹配。时间复杂度O(n+m)。
构建部分匹配表(next数组):记录模式串中每个子串前后缀的最长公共部分长度。
i++相当于给当前的子串增加了一个“尾巴”,我们只需要看新加的这个尾巴(s[i])能不能和前缀新加的那个成员(s[j])对上。
例如:
ababab next数组为[0,0,1,2,3,4];
aabcaa next数组为[0,1,0,0,1,2];
aabcaab next数组为[0,1,0,0,1,2,3];
1
2
3
4
5
6
7
8
9
10
11
| int[] next = new int[n];
int j = 0; // 前缀末尾,也是最长公共部分长度
for (int i = 1; i < n; i++) { // 后缀末尾
while (j > 0 && pattern.charAt(i) != pattern.charAt(j)) {
j = next[j - 1];// 回溯到上个匹配位置
}
if (pattern.charAt(i) == pattern.charAt(j)) {
j++;
}
next[i] = j;
}
|
28. 实现 strStr()
返回子串在主串中第一次出现的位置。
- 使用双指针遍历主串和子串。
1
2
3
4
5
6
7
8
9
10
11
12
| int left = 0, right = 0;
while (left < s.length()) {
if (s.charAt(left) == sub.charAt(right)) {
right++;
if (right == sub.length()) { return left-right+1; }
} else {
left -= right;// 下面有left++,不用加1
right = 0;
}
left++;
}
return -1;
|
- 使用KMP算法。
先构建模式串的next数组,然后使用双指针遍历主串和模式串。
此时回溯时不需要回溯主串指针,只需根据next数组回溯模式串指针。
459. 重复的子字符串
判断字符串是否由重复的子字符串构成。
- 将字符串与自身拼接,去掉首尾字符后,判断原字符串是否在新字符串中出现。
- 使用KMP算法,构建next数组。
1
2
3
4
5
6
7
8
| int n = s.length();
int[] next = new int[n];
for (int i = 1, j = 0; i < n; i++) {// i为后缀末尾,j为前缀末尾
while(j > 0 && s.charAt(i) != s.charAt(j)) { j = next[j-1]; }
if (s.charAt(i) == s.charAt(j)) { j++; }
next[i] = j;
}
if (next[n-1] > 0 && n % (n - next[n-1]) == 0) { return true; }// 注意判断条件,next[n-1]>0
|
栈和队列
- 用栈实现队列
使用两个栈实现,一个只用于输入,一个只用于输出。
1
2
3
4
5
6
7
8
9
10
| // 核心函数
// 输出栈为空时才将输入栈元素弹出压入输出栈
// 因此中途入队的元素不会影响出队顺序,每个元素都只翻转一次
private void dump() {
if (stackout.isEmpty()) {
while (!stackin.isEmpty()) {
stackout.push(stackin.pop());
}
}
}
|
用队列实现栈
将除了队列尾部的元素依次出队再入队,最后一个元素即为栈顶元素。
逆波兰表达式求值
遇到数字入栈,遇到运算符出栈两个数字进行运算,结果入栈。
滑动窗口最大值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| public int[] maxSlidingWindow(int[] nums, int k) {
int n = nums.length;
if (n == 0 || k == 0) { return new int[0]; }
int[] res = new int[n - k + 1];
Deque<Integer> queue = new ArrayDeque<>();
for (int i = 0; i < nums.length; i++) {
while (!queue.isEmpty() && nums[queue.peekLast()] <= nums[i]) {
queue.pollLast();
}// 出队所有比当前位置小的,因此队列中必为降序
queue.offerLast(i);// 入队
if (queue.peekFirst() <= i - k) {// 判断队首是否出窗口范围(用<=)
queue.pollFirst();
}
if (i >= k - 1) {
res[i - k + 1] = nums[queue.peekFirst()];
}
}
return res;
}
|
- 前K个高频元素
使用小顶堆维护前k个高频元素。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| public int[] topKFrequent(int[] nums, int k) {
Map<Integer, Integer> map = new HashMap<>();
for (int num : nums) {
map.put(num, map.getOrDefault(num, 0) + 1);
}
// 最小堆:按出现次数排序
Queue<Map.Entry<Integer, Integer>> pq =
new PriorityQueue<>((a, b) -> a.getValue() - b.getValue());
for (Map.Entry<Integer, Integer> entry : map.entrySet()) {// entrySet() 遍历键值对
pq.offer(entry);
if (pq.size() > k) {// 个数超过k,弹出优先级最高(最小)元素
pq.poll();
}
}
int[] result = new int[k];
for (int i = 0; i < k; i++) {
result[i] = pq.poll().getKey();
}
return result;
}
|
二叉树
基础知识
- 特殊二叉树:满二叉树、完全二叉树、平衡二叉树、二叉搜索树、堆。
- 满二叉树:每层节点数都达到最大值,深度为k时有2^k-1个节点。
- 完全二叉树:除最后一层外都是满的,最后一层节点从左到右连续排列。
- 平衡二叉树:任意节点的左右子树高度差不超过1。
- 二叉搜索树:左子树所有节点值<根节点值<右子树所有节点值。
- 堆:完全二叉树,父节点值总是大于/小于子节点值(大顶堆/小顶堆)。
- 遍历方式:前序、中序、后序、层序。
其实就是处理左右子节点的顺序不同:
前序:根->左->右 约等于对应自顶向下
中序:左->根->右
后序:左->右->根 约等于对应自底向上
层序:按层从上到下、从左到右遍历。
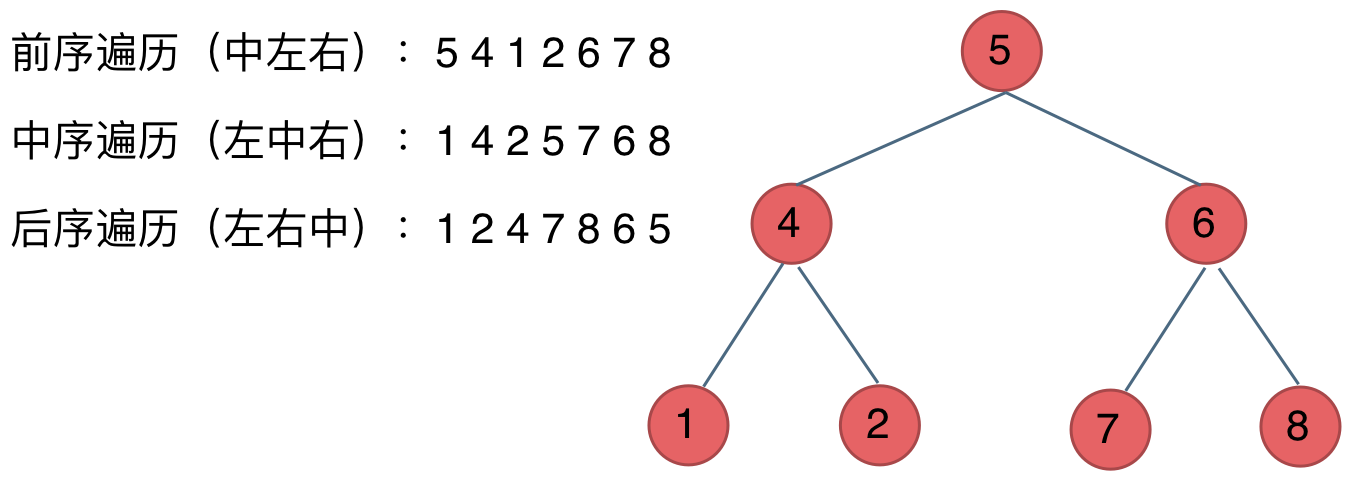
从整体视角看,dfs函数返回当前节点的左右子树(子树内部也按顺序排列)
可以看到前序遍历的分布为根,左子树,右子树
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| 递归中序遍历,前、后序即改变result.add位置
void dfs(TreeNode root, List<Integer> list) {
if (root == null) {
return;
}
dfs(root.left, result);// 左子树
result.add(root.val);// 代码处理部分
dfs(root.right, result);// 右子树
}
层序遍历
// 也可以是Queue<TreeNode> queue = new LinkedList<>(); Deque支持更多操作,性能更好
Deque<TreeNode> queue = new ArrayDeque<>();
queue.offer(root);
while (!queue.isEmpty()) {
int size = queue.size();// size为当前层节点数,避免处理下一层节点
List<Integer> level = new ArrayList<>();
for (int i = 0; i < size; i++) {
TreeNode node = queue.poll();
level.add(node.val);
if (node.left != null) { queue.offer(node.left); }
if (node.right != null) { queue.offer(node.right); }
}
result.add(level);
}
return result;
|
(处理节点时会按序访问其左右子节点。由于代码会自动拦截空节点,因此适用于任意形态的二叉树,无需局限于满二叉树)
通用遍历标记法:
压入null表示已处理该节点的子节点,可以直接读取它的值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| Stack<TreeNode> stack = new Stack<>();
stack.push(root);
while (!stack.isEmpty()) {
TreeNode node = stack.pop();
if (node != null) {
// 示例:中序
if (node.right != null) stack.push(node.right); // 右
stack.push(node); // 中
stack.push(null); // 标记位
if (node.left != null) stack.push(node.left); // 左
} else {
// 遇到null,说明下一个节点是需要被处理的根节点
result.add(stack.pop().val);
}
}
|
- 存储方式:顺序存储、链式存储。
顺序存储即使用数组,适合完全二叉树。节点i的左子节点为2i+1,右子节点为2i+2。
链式存储即使用节点类,适合各种二叉树。
递归问题
从局部到全局,每个节点的处理都遵循相同的原则,因此可以递归。
构建递归函数:
- 信息传递:需要谁的?给谁传递?
自底向上(110、236题):需要子节点信息,给父节点返回信息。虽然节点是从上到下访问的,但信息传递方向从下到上。
自顶向下(98、257题):需要父节点信息,给子节点传递信息。
- 递归出口:
节点为 null 或 叶子节点 时,做特殊处理。
题目
深度与路径类
引子:513. 找树左下角的值
方法1:递归
构建函数思路:根据信息判断
- 二叉树节点的信息:a.左右子节点,b.节点值。
需要的信息:c.当前节点所在深度。 - 函数需要完成的:
提供递归出口
进行处理(b,c)
访问左右子节点(a)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| private int maxDepth = 0;
private int leftmostValue;
public int findBottomLeftValue(TreeNode root) {
dfs(root, 1);
return leftmostValue;
}
private void dfs(TreeNode node, int depth) {
if (node == null) { return; }
if (depth > maxDepth) {
maxDepth = depth;
leftmostValue = node.val;
}
dfs(node.left, depth + 1);// 先访问左子节点,该函数会更新maxDepth,因此访问同一层右子节点时不会覆盖结果。
dfs(node.right, depth + 1);
}
方法2:层序遍历
调换左右节点入队顺序,每层最后一个被弹出的节点为最左节点,就无需额外的判断了。
public int findBottomLeftValue(TreeNode root) {
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
while (!queue.isEmpty()) {
root = queue.poll();
if (root.right != null) queue.offer(root.right);
if (root.left != null) queue.offer(root.left);
}
return root.val; // 最后一个被弹出的就是最左下角的
}
|
- 二叉树的最小深度
最大深度只需要看层序遍历的总层数,而最小深度需要在遍历过程中判断是否为叶子节点。
因为层序遍历自上而下、从左到右,因此当遇到第一个叶子节点时,当前层数即为最小深度。
第112题.路径总和 的层序遍历解法采用了两个队列同步出入队列,一个存储节点,一个存储当前路径和。不具体展开了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| // 层序遍历:当遇到第一个叶子节点时,当前层数即为最小深度。
while (!queue.isEmpty()){
int size = queue.size();
depth++;
TreeNode cur = null;
for (int i = 0; i < size; i++) {
cur = queue.poll();
if (cur.left == null && cur.right == null){ //直接返回最小深度
return depth;
}
if (cur.left != null) queue.offer(cur.left);
if (cur.right != null) queue.offer(cur.right);
}
}
// 递归
public int minDepth(TreeNode root) {
if (root == null) return 0;
int m1 = minDepth(root.left);
int m2 = minDepth(root.right);
// 注意:如果有一个子树为空,判断语句返回0,会导致结果错误,需要特殊处理。
// 如果有一个子树为空,返回 m1 + m2 + 1 (m1或m2有一个为0)
// 如果都不为空,返回 min(m1, m2) + 1
return (root.left == null || root.right == null) ? (m1 + m2 + 1) : Math.min(m1, m2) + 1;
}
|
- 路径总和 III
路径不要求从根节点开始,也不要求到叶子节点结束,但方向必须向下。
自顶向下传递从根节点到当前节点的前缀和,用Map记录某个前缀和出现过几次。
如果当前前缀和为curSum,目标路径和为targetSum,那么需要找到之前出现过的oldSum,使得:
1
2
| curSum - oldSum = targetSum
oldSum = curSum - targetSum
|
因此每到一个节点,就先统计 map.get(curSum - targetSum),再把当前curSum加入Map,继续遍历左右子树。
离开当前节点时,需要撤销当前前缀和,避免影响其他分支。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| public int pathSum(TreeNode root, int targetSum) {
Map<Long, Integer> map = new HashMap<>();
map.put(0L, 1);
return dfs(root, 0L, targetSum, map);
}
private int dfs(TreeNode node, long curSum, int targetSum, Map<Long, Integer> map) {
if (node == null) return 0;
curSum += node.val;
int count = map.getOrDefault(curSum - targetSum, 0);
map.put(curSum, map.getOrDefault(curSum, 0) + 1);
count += dfs(node.left, curSum, targetSum, map);
count += dfs(node.right, curSum, targetSum, map);
map.put(curSum, map.get(curSum) - 1);
return count;
}
|
- 二叉树中的最大路径和
父节点需要子节点信息(从子节点向上延伸的最大路径和),因此自底向上递归。
当前节点在路径中有两种可能的身份:
1.作为路径中间的一部分:向父节点传递最大值。由于路径继续向父节点延伸时不能分叉,因此选择左子树或右子树中的最大一边。
2.作为路径的顶点:同时连接左子树、当前节点、右子树,因此需要用额外变量记录答案。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| private int ans = Integer.MIN_VALUE;
public int maxPathSum(TreeNode root) {
dfs(root);
return ans;
}
private int dfs(TreeNode node) {
if (node == null) return 0;
int left = Math.max(0, dfs(node.left));
int right = Math.max(0, dfs(node.right));
ans = Math.max(ans, node.val + left + right);// 身份2
return node.val + Math.max(left, right);// 身份1
}
|
- 二叉树的所有路径
子节点需要父节点信息(路径),因此自顶向下递归。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| class Solution {
public List<String> binaryTreePaths(TreeNode root) {
List<String> res = new ArrayList<>();
constructPaths(root,"",res);
return res;
}
private void constructPaths(TreeNode node, String path, List<String> res) {
if (node!=null) {
path += Integer.toString(node.val);
if (node.left == null && node.right == null) {
res.add(path);
} else {
path+="->";
constructPaths(node.left,path,res);
constructPaths(node.right,path,res);
}
}
}
}
|
树的属性判断类
98. 验证二叉搜索树
自顶向下传递父节点范围,判断当前节点是否在区间内。
1
2
3
4
5
6
7
8
9
| public boolean isValidBST(TreeNode root) {
return isValidBST(root, Long.MIN_VALUE, Long.MAX_VALUE);// 注意这里Long大写L
}
private boolean isValidBST(TreeNode node, long min, long max) {
if (node == null) return true;
if (node.val <= min || node.val >= max) return false;
return isValidBST(node.left, min, node.val) && isValidBST(node.right, node.val, max);
}
|
101. 对称二叉树
1
2
3
4
5
6
7
8
9
| public boolean isSymmetric(TreeNode root) {
if (root == null) return true;
return dfs(root.left, root.right);
}
private boolean dfs(TreeNode left, TreeNode right) {
if (left == null && right == null) return true;
if (left == null || right == null || left.val != right.val) return false;
return dfs(left.left, right.right) && dfs(left.right, right.left);
}
|
- 平衡二叉树
父节点需要子节点信息(高度),因此自底向上递归。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| class Solution {
public boolean isBalanced(TreeNode root) {
return height(root)!=-1;
}
private int height(TreeNode node) {
if (node == null) {return 0;}// 递归出口
// 获取左右子树高度并剪枝
int leftHeight = height(node.left);
if (leftHeight==-1) {return -1;}// 剪枝
int rightHeight = height(node.right);
if (rightHeight==-1) {return -1;}// 剪枝
// 对信息进行处理
if (Math.abs(leftHeight-rightHeight) > 1) {return -1;}
// 返回当前节点高度
return Math.max(leftHeight,rightHeight)+1;
}
}
|
节点处理类
116. 填充每个节点的下一个右侧节点指针
给定一个完美二叉树,填充每个节点的 next 指针,使其指向下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| // 1. 递归,不适用于任意形态的二叉树
public Node connect(Node root) {
if (root == null) { return null; }
Node leftmost = root;
while (leftmost.left != null) {
Node head = leftmost;
while (head != null) {
head.left.next = head.right;// 同一父节点的左右子节点连接
if (head.next != null) {
head.right.next = head.next.left;// 不同父节点的子节点连接
}
head = head.next;// 同一层的下一个父节点
}
leftmost = leftmost.left;// 下一层的最左节点
}
return root;
}
// 2. 层序遍历,都适用
public Node connect(Node root) {
if (root == null) return null;
Queue<Node> queue = new LinkedList<>();
queue.offer(root);
while (!queue.isEmpty()) {
int size = queue.size();
Node prev = null;
for (int i = 0; i < size; i++) {
Node node = queue.poll();
if (prev != null) prev.next = node;
prev = node;
if (node.left != null) queue.offer(node.left);
if (node.right != null) queue.offer(node.right);
}
}
return root;
}
|
- 二叉树的最近公共祖先
传递的信息:当前节点及其子树是否包含p或q,自底向上
代码的设计:直接用null表示不包含;直接将节点作为返回值,不需要额外的变量记录答案。
对于四种情况的讨论:
1.均为空:不包含,返回null
2.一个空一个不空:两种情况,非空的那个节点要么表示包含了p或q;要么此时非空的那个已经在公共祖先节点上方,其指向的已经是公共祖先节点,回传即可
3.两个都非空:说明当前root即是公共祖先节点,回传
1
2
3
4
5
6
7
8
9
10
11
| public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if (root == null || root == p || root == q) {return root;}
TreeNode left = lowestCommonAncestor(root.left, p, q);
TreeNode right = lowestCommonAncestor(root.right, p, q);
// 对于left/right的四种情况判断(有有、有无、无有、无无)
if(left == null) return right;
if(right == null) return left;
return root;// 两个都非空
}
|
- 监控二叉树
题目描述:给定一个二叉树,我们在树的节点上安装摄像头,摄像头可以监视其父节点、自身和直接子节点。计算监控整棵树所需的最少摄像头数量。
解法:后序遍历(自底向上),根据左右子节点的状态判断自身状态,贪心决定是否放置摄像头。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| int ans=0;
public int minCameraCover(TreeNode root) {
if (dfs(root) == 0) {ans++;}
return ans;
}
// 定义三个状态:0:该节点未被覆盖
// 1:安装了摄像头;2:已被覆盖,但没摄像头
private int dfs(TreeNode node) {
if (node == null) {return 2;}
int left =dfs(node.left);
int right = dfs(node.right);
if (left == 0 || right == 0) {// 有一个没有就需要安装
ans++;
return 1;
}
if (left == 1 || right == 1) {return 2;}// 有子节点装了,被覆盖到
return 0;
}
|
- 左叶子之和
注意到叶子节点本身并不能判断其是否为左叶子节点。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| // 父级预判:通过root.left判断是左叶子。
public int sumOfLeftLeaves(TreeNode root) {
if (root == null) return 0;
int sum = 0;
if (root.left != null && root.left.left == null && root.left.right == null) {
sum += root.left.val;
}
return sum + sumOfLeftLeaves(root.left) + sumOfLeftLeaves(root.right);
}
// 叶子节点作为递归出口:添加标记
public int sumOfLeftLeaves(TreeNode root) {
return dfs(root, false); // 根节点不是任何人的左孩子
}
private int dfs(TreeNode node, boolean isLeft) {
if (node == null) return 0;
if (node.left == null && node.right == null) {
return isLeft ? node.val : 0;
}
// 左true 右false
return dfs(node.left, true) + dfs(node.right, false);
}
|
区间切分构造类
- 最大二叉树
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| public TreeNode constructMaximumBinaryTree(int[] nums) {
return build(nums,0,nums.length-1);
}
private TreeNode build(int[] nums, int left, int right) {
if (left>right) {return null;}// 注意等于号
int maxIndex = left;
for (int i = left+1; i <= right; i++) {
if (nums[i] > nums[maxIndex]) {
maxIndex = i;
}
}
TreeNode root = new TreeNode(nums[maxIndex]);
// 注意向下传递的左右边界
root.left = build(nums,left,maxIndex-1);
root.right = build(nums,maxIndex+1,right);
return root;
}
|
⭐106. 从中序与后序遍历序列构造二叉树
后序遍历顺序是 左 → 右 → 根,倒着读就是 根 → 右 → 左
从后序序列获取第一个根节点->在中序序列中找到,切分左右子树->从后序序列找到左右子树的根节点
前序序列也是同理
注意postIndex的全局/局部问题:
- 如果为全局指针,,则每次递归–;
- 如果为局部变量,则需要记录子树长度,根据区间长度计算。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| private Map<Integer, Integer> indexMap;
private int[] postorder;
private int postIndex;
public TreeNode buildTree(int[] inorder, int[] postorder) {
this.postorder = postorder;
this.postIndex = postorder.length - 1;// 从最后开始读取
this.indexMap = new HashMap<>();
for (int i = 0; i < inorder.length; i++) {
indexMap.put(inorder[i], i);
}
return build(0, inorder.length - 1);
}
private TreeNode build(int inLeft, int inRight) {
if (inLeft > inRight) {return null;}
int rootVal = postorder[postIndex--];
TreeNode root = new TreeNode(rootVal);
int rootIndex = indexMap.get(rootVal);
// 全局指针,根右左遍历的顺序不可以换
root.right = build(rootIndex + 1, inRight);
root.left = build(inLeft, rootIndex - 1);
return root;
}
// 前序数组的局部index写法
private TreeNode build(int preIndex, int begin, int end) {
if (begin>end) return null;
int rootVal = preorder[preIndex];
int inIndex = indexMap.get(rootVal);
TreeNode root = new TreeNode(rootVal);
int leftLen = inIndex - begin;
root.left = build(preIndex+1, begin, inIndex-1);
root.right = build(preIndex+leftLen+1, inIndex+1, end);
return root;
}
|
图论
399. 除法求值
DFS搜索:
用 Map<String, List> 建图。
每个查询 x / y,如果 x 或 y 不存在,返回 -1.0。
从 x 开始 DFS/BFS 找 y,沿途把边权相乘。
找到 y 时,当前乘积就是答案;找不到返回 -1.0。
并查集:
普通并查集只维护元素是否属于同一个集合;本题需要维护两个变量之间的倍数关系,因此使用带权并查集。
parent[x] 表示 x 的父节点,weight[x] 表示 x / parent[x] 的值。
经过find函数路径压缩后,weight[x] 会更新为 x / root 的值。
查询 a / b 时,如果 a、b 连通,答案为:a / b = (a / root) / (b / root) = weight[a] / weight[b]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| def calcEquation(self, equations, values, queries):
parent = {}
weight = {}
def find(x): # 递归寻找根root
if parent[x] != x:
original_parent = parent[x]
root = find(original_parent)
# 压缩路径到root
weight[x] *= weight[original_parent]
parent[x] = root
return parent[x]
for (a, b), val in zip(equations, values):
if a not in parent:
parent[a] = a
weight[a] = 1.0
if b not in parent:
parent[b] = b
weight[b] = 1.0
root_a = find(a)
root_b = find(b)
if root_a == root_b:
continue
# 之前不连通的建立连接
parent[root_a] = root_b
weight[root_a] = val * weight[b] / weight[a]
ans = []
for a, b in queries:
if a not in parent or b not in parent:
ans.append(-1.0)
continue
if find(a) != find(b):
ans.append(-1.0)
else:
ans.append(weight[a] / weight[b])
return ans
|
207. 课程表
拓扑排序:课程依赖关系可以看成有向图,[a, b] 表示学 a 之前必须先学 b,即 b -> a。
如果图中存在环,就不可能完成所有课程;如果能通过拓扑排序遍历所有课程,则可以完成。
使用入度数组 indegree 记录每门课还有多少前置课程未完成。
先把入度为 0 的课程加入队列,表示可以直接学习;每学完一门课,就将它指向的后续课程入度减 1。
如果某门后续课程入度变为 0,说明它的前置课程都已完成,可以加入队列。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| public boolean canFinish(int numCourses, int[][] prerequisites) {
List<List<Integer>> graph = new ArrayList<>();
for (int i = 0; i < numCourses; i++) {
graph.add(new ArrayList<>());
}
int[] indegree = new int[numCourses];
for (int[] p : prerequisites) {
int course = p[0];
int pre = p[1];
graph.get(pre).add(course);
indegree[course]++;
}
Queue<Integer> queue = new LinkedList<>();
for (int i = 0; i < numCourses; i++) {
if (indegree[i] == 0) {
queue.offer(i);
}
}
int count = 0;
while (!queue.isEmpty()) {
int cur = queue.poll();
count++;
for (int next : graph.get(cur)) {
indegree[next]--;
if (indegree[next] == 0) {
queue.offer(next);
}
}
}
return count == numCourses;
}
|
动态规划
动态规划:将复杂问题分解为更小子问题。
初始状态->子问题->最终状态 遵循相同的原则,因此可以递推。
不用去想复杂状态具体是怎么实现的,因为DP本就不是直接求解,而是一步步递推。
只需要通过一般的状态找出那个通用的状态转移方程,只要方程正确,复杂状态自然可以由初始情况慢慢得到。
核心要素:发现由子问题递推到复杂问题的状态转移方程。
- 将什么状态定义为dp数组(一般求什么就定义什么),注意状态初始化
- 状态转移方程
- 遍历顺序
二维DP的上一个状态有三种,左/上/左上。
题目
70. 爬楼梯
dp[i]: 爬到第i层楼梯,有dp[i]种方法
1
2
3
4
5
6
7
| dp[0] = 1;
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {// 一次能爬 1~m 步
if (i - j >= 0) { dp[i] += dp[i - j]; }
}
}
return dp[n];
|
状态转移方程为: dp[i] = sum(dp[i-j]) (1<=j<=m)
由于遍历时只用到前m项,可以用m个变量代替dp数组,降低空间复杂度。
746. 使用最小花费爬楼梯
1
2
3
| int dpi = Math.min(dp0+cost[i-2], dp1+cost[i-1]);
dp0 = dp1;
dp1 = dpi;
|
为什么dp0,dp1的更新只跨一步?只和遍历顺序有关。
遍历顺序为i++,遍历顺序不是最终路径。因此跨越一步或者两步与遍历顺序无关。
62. 不同路径
dp[i][j] = dp[i - 1][j] + dp[i][j - 1]
96. 不同的二叉搜索树
令 dp[i] 表示 i 个节点能构成的 BST 数量,dp[0]=1。
对于节点数为i(1<=i<=n),选择j(0 <= j <= i-1)为左子树节点数(根节点占一个),此时左子树由j个节点构成,右子树由i-j-1个节点构成。
因此子问题求解为 dp[i]=sum(dp[j] * dp[i-j-1]),即状态转移方程。
打家劫舍
198. 打家劫舍
数组中每个数都大于0,因此不可能连续跳过两个。
1
2
3
4
5
6
7
8
| int n = nums.length;
int[] dp = new int[n];
dp[0] = nums[0];
dp[1] = Math.max(nums[0],nums[1]);
for (int i = 2; i < n; i++) {
dp[i] = Math.max(dp[i - 1], dp[i - 2] + nums[i]);
}
return dp[n];
|
- 打家劫舍Ⅲ
可能出现连续跳过的情况:
比如对于某个节点,左子树的孙子节点收益巨高,而右子树是子节点收益巨高,因此需要连续跳过根节点 和 左子节点。
每个节点返回取/不取自己值的两种可能,供上层挑选。
res0=max(left0,left1)+max(right0,right1)
res1=node.val+left0+right0
买卖股票
原题允许一天多次买卖,因此只要正收益都直接加上去。
买卖股票的最佳时机 IV
最多交易k次,用两个数组:
buy[i]:完成最多 i 次交易时,当天购买股票的最大收益
sell[i]:完成最多 i 次交易时,当天售卖股票的最大收益
1
2
3
4
5
6
7
8
9
10
11
12
13
| def maxProfit(self, k, prices):
if not prices:
return 0
buy = [-float("inf")] * (k + 1)
sell = [0] * (k + 1)
for price in prices:
for i in range(1, k + 1):
buy[i] = max(buy[i], sell[i - 1] - price) # 之前price的第i次持有收益,当前price下买入后的持有收益
sell[i] = max(sell[i], buy[i] + price)
return sell[k]
|
对于[1,2,3,0,4],前三天buy[1]、buy[2]相同,一次和两次的交易最终结果一样,没有必要进行第二次交易。
309. 买卖股票的最佳时机含冷冻期
分解成子问题:每天只根据前一天处理当天三个状态的最大值
三个状态不是说「同一天同时进行三种操作」,而是给出当天的全部三种可能性,是给后续转移使用的候选状态。
状态转移:由于必须在再次购买前出售掉之前的股票,可得
- 当天要买,则有两种来源:继承之前持有还没买/昨天是rest,扣除今天price
- 当天要卖,来源是之前持有的+当天price
- 当天休息,则要么刚卖完在冷冻/要么昨天也在休息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| def maxProfit(self, prices):
buy = -prices[0]# **不是说第一天必须买,是候选状态**
sold = 0
rest = 0
for price in prices[1:]:
prev_buy = buy
prev_sold = sold
prev_rest = rest
buy = max(prev_buy, prev_rest - price)
sold = prev_buy + price
rest = max(prev_rest, prev_sold)
return max(sold, rest)
|
字符串编辑
- 编辑距离
用 D[i][j] 表示 A 的前 i 个字母和 B 的前 j 个字母之间的编辑距离。
转移方程:如果A B新遍历到的字母相同,则最后一项+0;不同则+1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| def minDistance(self, word1: str, word2: str) -> int:
m, n = len(word1), len(word2)
dp = [[0] * (n + 1) for _ in range(m + 1)]
# 这里为什么是n+1,m+1?
# 因为dp的i、j表示的是前几个字符,对应字符串下标i-1 j-1
for i in range(m + 1):
dp[i][0] = i
for j in range(n + 1):
dp[0][j] = j
for i in range(1, m + 1):
for j in range(1, n + 1):
if word1[i - 1] == word2[j - 1]:
dp[i][j] = dp[i - 1][j - 1]
else:
dp[i][j] = min(
dp[i - 1][j], # 删除
dp[i][j - 1], # 插入
dp[i - 1][j - 1] # 替换
) + 1
return dp[m][n]
|
- 最长公共子序列
text1 = “abcde”, text2 = “ace” ;输出:3
经典二维DP。
dp[i][j]:text1 前 i 个字符 和 text2 前 j 个字符的最长公共子序列长度。
转移方程:如果A B新遍历到的字母相同,则最后一项+1;不同则不加。
1
2
3
4
5
6
7
8
9
10
11
12
| def longestCommonSubsequence(self, text1, text2):
m, n = len(text1), len(text2)
dp = [[0] * (n + 1) for _ in range(m + 1)]
for i in range(1, m + 1):
for j in range(1, n + 1):
if text1[i - 1] == text2[j - 1]:
dp[i][j] = dp[i - 1][j - 1] + 1
else:
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1])
return dp[m][n]
|
- 不同的子序列
s = “babgbag”, t = “bag”;输出不同组合种数:5
不需要考虑最终具体怎么组合(即使是答案要输出子序列),只需要考虑每一步状态,然后遍历过去。
dp[i][j]:s 前 i 个字符中,能组成 t 前 j 个字符的不同子序列个数
转移方程中的项:s[i - 1] == t[j - 1],则当前字符有用;如果不相等,则该字符是要被删去的,不用。
- dp[i - 1][j - 1]:用上当前字符
- dp[i - 1][j]:不用当前字符
为什么相等时DP是两个相加:当前字符可以选择“用”或“不用”。用当前字符时,方案数来自 dp[i-1][j-1];不用当前字符时,方案数来自 dp[i-1][j]。
因为“用当前字符”和“不用当前字符”是互斥的两类方案,不会重复计数;而题目要求的是方案总数,所以可以把两类方案数相加。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| def numDistinct(self, s, t):
m, n = len(s), len(t)
dp = [[0] * (n + 1) for _ in range(m + 1)]
for i in range(m + 1):# 都包含一个空串
dp[i][0] = 1
# dp的i、j表示的是前几个字符,对应字符串下标i-1 j-1
for i in range(1, m + 1):
for j in range(1, n + 1):
if s[i - 1] == t[j - 1]:
dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j]
else:
dp[i][j] = dp[i - 1][j]
return dp[m][n]
|
- 回文子串
动归法:通过boolean dp[i][j]记录i-j之间是否为回文串,但空间复杂度是N^2.
状态转移:if (s.charAt(i) == s.charAt(j) && (i - j < 2 || dp[i + 1][j - 1])) {dp[i][j] = true;}
- i - j < 2 表示当前为中心(i-j是1个或2个字符)
- dp[i + 1][j - 1] 表示范围更小的子串是回文串
中心扩展法:分别以单个字符和两个字符为中心。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| class Solution {
public int countSubstrings(String s) {
int ans = 0;
for (int i = 0; i < s.length(); i++) {
ans += expand(s, i, i);
ans += expand(s, i, i + 1);
}
return ans;
}
private int expand(String s, int left, int right) {
int count = 0;
while (left >= 0 && right < s.length()
&& s.charAt(left) == s.charAt(right)) {
count++;
left--;
right++;
}
return count;
}
}
|
区间DP
区间DP适用于:一次选择会把问题拆成左右两个区间,且当前选择的收益依赖区间边界。
这类问题通常不能直接贪心,因为当前局部最优会改变后续的相邻关系,局部收益无法独立决定全局最优。
312. 戳气球
不能用贪心:如果每次选择当前收益最大的气球,戳破后它左右两边会变成新的相邻元素,后续收益被当前选择改变。
因此不能只看“当前戳哪个最赚”,而要枚举某个区间里最后一个被戳破的气球。
DP定义为开区间(i, j)内的最大收益。
在区间 (i, j) 中,假设最后戳破的气球是 k,那么最后 k 左右相邻的一定是边界 i 和 j,收益确定为:
1
| dp[i][j] = max(dp[i][k] + dp[k][j] + points[i] * points[k] * points[j])
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| public int maxCoins(int[] nums) {
int n = nums.length;
int[] points = new int[n + 2];
points[0] = 1;
points[n + 1] = 1;
for (int i = 0; i < n; i++) {
points[i + 1] = nums[i];
}
int[][] dp = new int[n + 2][n + 2];
for (int len = 2; len <= n + 1; len++) {
for (int left = 0; left + len <= n + 1; left++) {
int right = left + len;
for (int k = left + 1; k < right; k++) {// 注意从left+1不是left开始
dp[left][right] = Math.max(
dp[left][right],
dp[left][k] + dp[k][right] + points[left] * points[k] * points[right]
);
}
}
}
return dp[0][n + 1];
}
|
背包问题
背包问题先判断物品是否可以重复选择,再判断 dp 表示什么含义。
- 01背包:每个物品只能选一次,容量遍历必须倒序,避免同一个物品被重复使用。
- 完全背包:每个物品可以选多次,容量遍历通常正序,让当前物品可以继续参与后续状态。
- 多维费用背包:限制不止一个,例如同时限制 0 的个数和 1 的个数。
一维 DP 中,倒序是为了防止当前物品被重复使用;正序是为了允许当前物品被重复使用。因此遍历顺序完全背包从小到大,01背包从大到小。
为什么?下面正序遍历的例子中:
dp[2] = dp[0] + value
dp[4] = dp[2] + value
dp[4] 用到了刚更新的 dp[2],等于同一个物品用了两次。
dp[j] 的常见含义:
- 最大价值-max:
dp[j] = Math.max(dp[j], dp[j - cost] + value) - 最少数量-min:
dp[j] = Math.min(dp[j], dp[j - cost] + 1) - 是否可达-bool:
dp[j] = dp[j] || dp[j - cost] - 方案数量-累加:
dp[j] += dp[j - cost]
01背包
每个物品只能选一次,内层容量倒序。
最大价值问题
1
2
3
4
5
6
7
8
9
10
| // M 种材料,costs[i],values[i];背包总空间为 N
int[] dp = new int[N + 1];
for (int i = 0; i < M; i++) {
// 内层循环j--。同746题,遍历顺序!=最终路径
for (int j = N; j >= costs[i]; j--) {// 01背包倒序,完全背包正序
dp[j] = Math.max(dp[j], dp[j - costs[i]] + values[i]);
// 不选择or选择
}
}
return dp[N];
|
是否可达
416. 分割等和子集
[1,5,11,5] -> true
转化为 01背包:能否从 nums 中选出若干个数,使其和为 sum / 2。
背包容量为 sum / 2,物品重量为 num,dp[j] 表示容量 j 是否可以被凑出。
1
2
3
4
5
6
7
8
9
10
| if (sum % 2 != 0) { return false; }
int target = sum/2;
boolean[] dp = new boolean[target+1];
dp[0] = true;
for (int num : nums) {
for (int j = target; j >= num; j--) {
dp[j] = dp[j] || dp[j-num];
}
}
return dp[target];
|
方案数量
494. 目标和
给 nums 中每个数添加 + 或 -,使表达式结果等于 target。
设正数集合和为 pos,负数集合和为 neg:
1
2
3
| pos - neg = target
pos + neg = sum
pos = (sum + target) / 2
|
问题转化为:从 nums 中选出若干个数,使其和为 pos,一共有多少种选法。
dp[j] 表示凑出和 j 的方案数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| public int findTargetSumWays(int[] nums, int target) {
int sum = 0;
for (int num : nums) {
sum += num;
}
if (Math.abs(target) > sum || (sum + target) % 2 != 0) {
return 0;
}
int pos = (sum + target) / 2;
int[] dp = new int[pos + 1];
dp[0] = 1;
for (int num : nums) {
for (int j = pos; j >= num; j--) {
dp[j] += dp[j - num];
}
}
return dp[pos];
}
|
完全背包
每个物品可以重复选择,内层容量正序。
322. 零钱兑换
给定硬币面额 coins 和总金额 amount,求凑成 amount 所需的最少硬币数。
dp[j] 表示凑成金额 j 所需的最少硬币数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| public int coinChange(int[] coins, int amount) {
int max = amount + 1;
int[] dp = new int[amount + 1];
Arrays.fill(dp, max);
dp[0] = 0;
for (int coin : coins) {
for (int j = coin; j <= amount; j++) {
dp[j] = Math.min(dp[j], dp[j - coin] + 1);
}
}
return dp[amount] == max ? -1 : dp[amount];
}
|
多维费用背包
474. 一和零
每个字符串只能选一次,因此仍然是 01背包;但每个物品有两个费用:0 的个数和 1 的个数。
dp[i][j] 表示最多使用 i 个 0、j 个 1 时,能选出的字符串最大数量。
由于每个字符串只能选一次,两个容量都要倒序遍历。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| public int findMaxForm(String[] strs, int m, int n) {
int[][] dp = new int[m + 1][n + 1];
for (String str : strs) {
int zero = 0;
int one = 0;
for (char c : str.toCharArray()) {
if (c == '0') {
zero++;
} else {
one++;
}
}
for (int i = m; i >= zero; i--) {
for (int j = n; j >= one; j--) {
dp[i][j] = Math.max(dp[i][j], dp[i - zero][j - one] + 1);
}
}
}
return dp[m][n];
}
|
贪心算法
- 加油站
如果从加油站A出发最远只能到达加油站B,那么A B之间的任何一个加油站作为起点,都不可能越过B点。
所以下一个出发点直接选为(B+1),使得只需要遍历一次数组。
(题目规定存在解是唯一的,因此只要totalOil证明存在后,新的index无需循环遍历数组证明存在)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| public int canCompleteCircuit(int[] gas, int[] cost) {
int totalOil = 0;
int index = 0;
int currOil = 0;
for (int i = 0; i < gas.length; i++) {
int diff = gas[i] - cost[i];
totalOil += diff;
currOil += diff;
if (currOil < 0) {
index = i+1;
currOil = 0;
}
}
return totalOil < 0 ? -1 : index;
}
|
- 跳跃游戏 II
返回到达 n - 1 的最小跳跃次数。
注意,nums数组的值表示在该位置可以跳跃的最大距离,可以跳到该距离内任意一个点。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| public int jump(int[] nums) {
int cnt = 0;
int max = 0;
int end = 0;
for (int i = 0; i < nums.length-1; i++) {
max = Math.max(max, i+nums[i]);
// 当前一跳覆盖范围是i~end之间,范围内的每个点都可以作为下一跳的出发点
// 不关心具体在哪个点起跳,只关心最远范围,更新max
if (i==end) {
cnt++;
end = max;
}
}
return cnt;
}
|
- 最长递增子序列
贪心+二分,同一长度下让子序列末尾值尽可能小(通过替换实现)
具体实现:遍历 nums 中的每个数 x
- 如果 x 比所有结尾都大,追加到 tails
- 否则用二分找到第一个 >= x 的位置并替换它
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| public int lengthOfLIS(int[] nums) {
int[] tails = new int[nums.length];
int size = 0;
// tail[k]表示长度k+1的子序列末位值
// tails 列表一定是严格递增的
for (int num : nums) {
int left = 0;
int right = size;
while (left < right) {
int mid = left + (right - left) / 2;
if (tails[mid] < num) {left = mid + 1;
} else {right = mid;}
}
tails[left] = num;
if (left == size) {size++;}
}
return size;
}
|
例:[10,9,2,5,3],第一轮遍历10进入tails,并size++;
第二轮9替换了tails[0]的10;第三轮2替换了9;
第四轮5加到tails[1];第五轮3替换5。
- 单调递增的数字
如果不递增,则将该位开始的低位设为9并借位减一。
从后往前遍历。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| public int monotoneIncreasingDigits(int n) {
String s = Integer.toString(n);
char[] chars = s.toCharArray();
// start 记录从哪一位开始全部变为 9
int start = chars.length;
for (int i = chars.length-1; i > 0; i--) {
if (chars[i-1] > chars[i]) {
chars[i-1]--;
start = i;
}
}
for (int i = start; i < chars.length; i++) {
chars[i] = '9';
}
return Integer.valueOf(String.valueOf(chars));
}
|
两个维度
⭐135. 分发糖果
问题有两个维度的约束,既要和左边比又要和右边比。
分别从左右两个方向遍历。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| public int candy(int[] ratings) {
int n = ratings.length;
int[] candyVec = new int[n];
Arrays.fill(candyVec, 1);
// 从前向后遍历
for (int i = 1; i < ratings.length; i++) {
if (ratings[i] > ratings[i-1]) {
candyVec[i] = candyVec[i-1] + 1;
}
}
// 从后向前遍历
for (int i = ratings.length-1; i >= 1; i--) {
if (ratings[i-1] > ratings[i]) {
candyVec[i-1] = Math.max(candyVec[i-1], candyVec[i]+1);
}
}
int result = 0;
for (int s : candyVec) {
result += s;
}
return result;
}
// 如果candy数组不赋初始值1,则如下表示
for (int i = 0; i < n; i++) {// 前向后遍历
if (i > 0 && ratings[i] > ratings[i - 1]) {
candyVec[i] = candyVec[i - 1] + 1;
} else {candyVec[i] = 1;}
}
|
- 根据身高重建队列
先按身高降序排序,再按k值直接插入(小个子插入不影响高个子)
注意:比较器返回负数则升序,返回正数则降序。通过改变比较逻辑实现不同排序。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| public int[][] reconstructQueue(int[][] people) {
// 身高从大到小排(身高相同,k小的站前面)
Arrays.sort(people, (i,j) -> {
if (i[0] == j[0]) return i[1] - j[1];// k小在前
return j[0] - i[0];// h小在后
});
ArrayList<int[]> que = new ArrayList<>();
for (int[] p : people) {que.add(p[1], p);}
// 因为降序排序,因此k值就是p应该在的索引位置
return que.toArray(new int[que.size()][]);
}
|
区间调度
435. 无重叠区间
返回需要移除的重叠区间的最小数量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| public int eraseOverlapIntervals(int[][] intervals) {
if (intervals.length == 0) return 0;
// 按区间的结束位置升序排序
Arrays.sort(intervals, (a,b) -> {return a[1] - b[1];});
int count = 1; // 记录非重叠区间的数量,初始为1
int edge = intervals[0][1]; // 记录当前非重叠区间的右边界
for (int i = 1; i < intervals.length; i++) {
if (intervals[i][0] >= edge) {// 注意此处,大于右边界
count++;
edge = intervals[i][1];
}
}
return intervals.length - count;
}
|
- 合并区间
合并所有重叠的区间
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| public int[][] merge(int[][] intervals) {
if (intervals.length <= 1) {return intervals;}
Arrays.sort(intervals, (a, b) -> a[0] - b[0]);// 起点升序排序
List<int[]> res = new ArrayList<>();
int[] curr = intervals[0];
res.add(curr);
for (int[] interval : intervals) {
int currEnd = curr[1];
int nextStart = interval[0];
int nextEnd = interval[1];
if (currEnd >= nextStart) {
curr[1] = Math.max(curr[1], nextEnd);// res中存的是curr地址,会同步更新
} else {
curr = interval;
res.add(curr);
}
}
return res.toArray(new int[res.size()][]);
}
|
回溯算法
回溯通常维护一个全局的共享状态。大多应用于在不同的分支中探索 并 穷举所有可能性。
回溯的题目代码都大同小异。
39. 组合总和
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| public List<List<Integer>> combinationSum(int[] candidates, int target) {
List<List<Integer>> result = new ArrayList<>();
backtrack(candidates, target, 0, new ArrayList<>(), result);
return result;
}
private void backtrack(int[] candidates, int target, int start, List<Integer> path, List<List<Integer>> result) {
if (target == 0) {
result.add(new ArrayList<>(path));
return;
}
for (int i = start; i < candidates.length; i++) {
if (candidates[i] <= target) {
path.add(candidates[i]);
backtrack(candidates, target - candidates[i], i, path, result);
// 此处可以选择重复,因此start还是i。对于40题非重复就是i+1
path.remove(path.size() - 1);
}
}
}
|
79. 单词搜索
遍历每一个起点,dfs每次探索四个方向,通过边界判断返回。
注意修改当前位置字符,dfs完后改回。回溯就体现在这里。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| public boolean exist(char[][] board, String word) {
int m = board.length;
int n = board[0].length;
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (dfs(board, word, i, j, 0)) {
return true;
}
}
}
return false;
}
private boolean dfs(char[][] board, String word, int i, int j, int k) {
if (k == word.length()) {return true;}
if (i < 0 || i >= board.length || j < 0 || j >= board[0].length || board[i][j] != word.charAt(k)) {
return false;
}
char temp = board[i][j];
board[i][j] = '*';// 将当前位改为非字母,避免后续重复使用。注意是单引号符合char,不可以是双引号
boolean res = dfs(board, word, i+1, j, k + 1) ||
dfs(board, word, i-1, j, k + 1) ||
dfs(board, word, i, j+1, k + 1) ||
dfs(board, word, i, j-1, k + 1);
board[i][j] = temp;
return res;
}
|
131. 分割回文串
子字符串是连续的,因此如果当前不是回文串就不用往深探索了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| class Solution {
public List<List<String>> partition(String s) {
List<List<String>> res = new ArrayList<>();
dfs(s, 0, new ArrayList<>(), res);
return res;
}
public void dfs(String s, int start, List<String> path, List<List<String>> res){
if(start == s.length()){
res.add(new ArrayList<>(path));
return;
}
for(int i=start;i<s.length();i++){
if(isPalindrome(s,start,i)){
path.add(s.substring(start,i+1));// 左闭右开,所以到i+1
dfs(s,i+1,path,res);
path.remove(path.size()-1);
}
}
}
private boolean isPalindrome(String s, int begin, int end){
while(begin<end){
if(s.charAt(begin++)!=s.charAt(end--)){ return false; }
}
return true;
}
}
|
- 递增子序列
主要注意去重的方式。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| public List<List<Integer>> findSubsequences(int[] nums) {
List<List<Integer>> res = new ArrayList<>();
backtrack(nums, 0, new ArrayList<>(), res);
return res;
}
private void backtrack(int[] nums, int start, List<Integer> path, List<List<Integer>> res) {
if (path.size() >= 2) {
res.add(new ArrayList<>(path));
}
Set<Integer> used = new HashSet<>();
for (int i = start; i < nums.length; i++) {
if ((!path.isEmpty() && nums[i] < path.get(path.size()-1)) || used.contains(nums[i])) {
continue;
}
used.add(nums[i]);
path.add(nums[i]);
backtrack(nums, i+1, path, res);
path.remove(path.size()-1);
}
}
|
301. 删除无效的括号
字符串 + DFS/回溯 + 剪枝:双向扫描只是发现多余左右括号的方式,核心仍是在候选位置中尝试删除一个括号并递归。
从左到右处理多余的右括号,反转字符串后再用同样逻辑处理多余的左括号;跳过连续重复括号可以避免生成重复结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| class Solution:
def removeInvalidParentheses(self, s: str) -> List[str]:
res = []
self.solve(s, res, 0, 0, '(', ')')
return res
def solve(self, s: str, res: List[str], last_i: int, last_j: int,
open_ch: str, close_ch: str) -> None:
balance = 0
for i in range(last_i, len(s)):
if s[i] == open_ch:
balance += 1
elif s[i] == close_ch:
balance -= 1
if balance < 0:
for j in range(last_j, i + 1):
if s[j] == close_ch and (j == last_j or s[j - 1] != close_ch):
new_s = s[:j] + s[j + 1:]
self.solve(new_s, res, i, j, open_ch, close_ch)
return
reversed_s = s[::-1]
if open_ch == '(':
self.solve(reversed_s, res, 0, 0, close_ch, open_ch)
else:
res.append(reversed_s)
|
单调栈/队列
适用于需要找到第一个满足条件的元素的题目。
可以理解为排队,每次遇到新元素,while比较栈顶元素与新元素的关系?满足则出队:不满足继续排队。
新元素第一次肯定入队。因为比新元素小/大的元素都会被弹出。
单调栈的本质是空间换时间,在一次遍历中维护一个单调递增/递减的栈。
题目
42. 接雨水
当前元素作为坑底,找到左右第一个比它更高的元素,计算雨水量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| // 双指针法:从两端向中间遍历,更新左右最大高度,计算雨水量。
public int trap(int[] height) {
int left = 0, right = height.length - 1;// 双指针
int leftMax = 0, rightMax = 0;
int ans = 0;
while (left<right) {
if (height[left]<height[right]) {// 短板效应,更新较矮的指针
if (height[left] >= leftMax) {leftMax=height[left];}
else {ans += leftMax-height[left];}
left++;
} else {
if (height[right] >= rightMax) {rightMax = height[right];}
else {ans += rightMax-height[right];}
right--;
}
}
return ans;
}
// 单调栈法:遍历数组时,单调栈会找到当前元素作为*坑底*,左右第一个比它更高的元素,计算雨水量。
// 完备性讨论:算法遍历了每个元素,找到其对应的最大左右边界,因此算法是完备的。
public int trap(int[] height) {
int ans = 0;
Deque<Integer> stack = new ArrayDeque<>();
for (int i = 0; i < height.length; i++) {
while (!stack.isEmpty() && height[i] > height[stack.peek()]) {
int top = stack.pop();
if (stack.isEmpty()) { break; }
int left = stack.peek();
int width = i - left - 1;
int boundedHeight = Math.min(height[i], height[left]) - height[top];
ans += width * boundedHeight;
}
stack.push(i);
}
return ans;
}
|
⭐84. 柱状图中最大的矩形
当前元素作为矩形高度。
接雨水找到两侧第一个比当前柱子更高的柱子,计算面积;本题找到两侧第一个比当前柱子更矮的柱子,计算面积。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| public int largestRectangleArea(int[] heights) {
Stack<Integer> stack = new Stack<>();
int maxArea = 0;
for (int i = 0; i <= heights.length; i++) {
int currentHeight = (i == heights.length) ? 0 : heights[i];// 最后多加一个0,保证所有柱子都能出栈
while (!stack.isEmpty() && currentHeight < heights[stack.peek()]) {
int height = heights[stack.pop()];
int width = stack.isEmpty() ? i : i - stack.peek() - 1;
maxArea = Math.max(maxArea, height * width);
}
stack.push(i);
}
return maxArea;
}
// 双指针法:预处理每个柱子左右第一个比它更矮的柱子索引,计算面积(minRightIndex[i]-minLeftIndex[i]-1)*heights[i]。
|
完备性讨论:
- 怀疑:对于1 4 2 3中的4来说,其左右均边没有更高的柱子,面积为4。但其组成的最大矩形面积应为4 2 3组成的6。
4 2 3组成的6实际是以2为高求得的矩形面积,而不是以4为高。
这并不代表算法不完备,因为算法的目标是遍历每个柱子为高的最大矩形面积,之后比较出全局最大面积。而不是直接找到全局最大矩形面积。
- 证明:算法遍历了以每根柱子i为高的矩形面积,并通过单调栈找到每根柱子对应的最大宽度。
85. 最大矩形
通过遍历每一行,将矩阵问题转化为上题的直方图问题。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (matrix[i][j] == '1') {
heights[j] += 1;
} else {
heights[j] = 0;
}
}
maxArea = Math.max(maxArea, maxRecArea(heights));
}
// 处理函数
private int maxRecArea(int[] heights) {
int n = heights.length;
Stack<Integer> stack = new Stack<>();
int maxArea = 0;
int[] h = new int[n + 2];
System.arraycopy(heights, 0, h, 1, n);
for (int i = 0; i < h.length; i++) {
while (!stack.isEmpty() && h[i] < h[stack.peek()]) {
int height = h[stack.pop()];
int width = i - stack.peek() - 1;
maxArea = Math.max(maxArea, height * width);
}
stack.push(i);
}
return maxArea;
}
|
739. 每日温度
ans[i]求第一个比第i天温度高的日期距离i几天。
解题需要获取某天温度和更高温度的索引差,因此单调栈存放索引。
1
2
3
4
5
6
7
8
| for (int i = 0; i < n; i++) {
int currentTemp = temperatures[i];
// 当栈不为空,且当前温度大于栈顶索引对应的温度时
while (!stack.isEmpty() && currentTemp>temperatures[stack.peek()]) {
ans[stack.pop()] = i-prevIndex;
}
stack.push(i);
}
|
496. 下一个更大元素 I
找出 nums1 中每个元素在 nums2 中的下一个更大元素,没有则返回-1。
结果要求元素的值,因此单调栈存放元素值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| public int[] nextGreaterElement(int[] nums1, int[] nums2) {
// Map 用于存储 nums2 中每个元素及其对应的下一个更大元素
Map<Integer, Integer> map = new HashMap<>();
Deque<Integer> stack = new ArrayDeque<>();
// 遍历 nums2 构建单调栈
for (int num : nums2) {
while (!stack.isEmpty() && num>stack.peek()) {
map.put(stack.pop(),num);
}
stack.push(num);
}
int[] res = new int[nums1.length];
for (int i = 0; i < nums1.length; i++) {
res[i] = map.getOrDefault(nums1[i],-1);// 没有更大的元素,返回-1
}
return res;
}
|
503. 下一个更大元素 II
注意要循环数组,注意三点:
1.需要遍历两遍数组for (int i = 0; i < 2*n; i++)
2.栈内存放索引时需要对n取模stack.push(i%n)
3.只有i < n时才入栈,保证栈内元素索引不重复
1
2
3
4
5
6
7
8
9
| for (int i = 0; i < 2*n; i++) {
int num = nums[i%n];
// 单调栈逻辑:如果当前元素大于栈顶索引对应的元素
while (!stack.isEmpty() && num>nums[stack.peek()]) {
res[stack.pop()] = num;
}
// 只需要在第一轮遍历时将索引入栈
if (i<n) stack.push(i);
}
|