语法基础
权限修饰符 (范围从小到大)
private:仅在同一个类中可见。
default(无修饰符):同一个包中可见。
protected:同一个包 和 不同包的子孙类 中可见。
public:所有地方都可见。
变量类型 (Variables)
内存管理简介
虚拟机栈(VM Stack)—— 线程私有区域
- 结构:当前线程执行的所有方法信息(如:栈帧1
main、栈帧2、栈帧3 当前方法)。 - 存储:局部变量(包括基本数据类型的值,以及指向堆中对象的“对象引用”)。
- 特点:随线程/方法结束而自动销毁。
- 结构:当前线程执行的所有方法信息(如:栈帧1
堆区(Heap)—— 属于进程,被线程共享
- 存储:绝大多数创建出来的对象实例,以及包含在这些对象当中的实例变量(非 static 成员变量)。
方法区(Method Area)—— 属于进程,被线程共享
- 说明:本地内存中的元空间(Metaspace)。
- 存储:类信息、静态变量(静态变量仅在此处留存一份)、常量。
1. 成员变量 (Field)
定义在类中、方法外。
- 实例变量:属于对象,随对象创建于堆内存中。可用
public/private等权限修饰符封装。 - 静态变量(类变量):必须用
static修饰,也可以添加权限修饰符。属于类,方法区内只有一份,被所有对象共享。推荐使用类名.变量名访问。 - 常量:通常用
public static final修饰。内存中只有一份且不可变,命名规范为全大写(如MAX_SIZE)。
2. 局部变量 (Local Variable)
定义在方法内、代码块内或参数列表中。
- 存放在栈内存中,方法执行结束即销毁。
- 修饰符严格:除
final外,不能使用任何其他修饰符。 (可见性仅在方法内,public/private等修饰符无效;加载时机与static冲突) - 必须初始化:局部变量没有默认初始值,使用前必须显式赋值。
3. final 变量的赋值时机
- final 成员变量:必须在声明时、实例代码块中或构造器中执行结束前完成赋值。
- final 静态变量:必须在声明时或静态代码块中完成赋值。
- final 局部变量:只要确保在使用前赋值一次即可(可以先声明再赋值)。
| |
实例方法、静态方法 (Methods)
- 静态方法:由
static修饰,属于类。常用于main方法、工具类。
- 使用场景:只需完成功能,而不需要访问具体对象的数据时。
- 优势:调用方便(直接通过类名调用),无需创建对象,节省内存。(建议私有化工具类的构造器以防止实例化) 不能访问类的非静态成员变量和方法。
- 实例方法:属于对象,由对象名访问。可以访问所有成员变量和方法。
方法重载/重写
方法重载:在同一个类中,方法名相同,但参数列表不同(参数个数、类型或顺序不同),返回值类型可以不同(如果仅有返回值类型不同而参数列表相同,会导致编译错误)。
方法重写:子类继承父类后,子类对父类中已有方法进行重新实现,方法名、参数列表必须完全相同,返回值类型相同或范围更小,且修饰符不能比父类严格。
父类的私有方法、静态方法不能被重写。
使用 @Override 校验注解检查重写的方法是否符合规范。
重载(Overload):编译时多态(方法名相同,参数不同)。 重写(Override):运行时多态(子类重写父类的方法)。
SOLID原则
- 单一职责原则(Single Responsibility Principle):一个类应该只有一个引起它变化的原因,即一个类只负责一项职责。
- 开闭原则(Open-Closed Principle):软件实体(类、模块、函数等)应该对扩展开放,对修改关闭。即在不修改现有代码的基础上,可以通过添加新代码来扩展功能。
- 里氏替换原则(Liskov Substitution Principle):子类对象应该能够替换父类对象,且该替换不会影响程序的行为。
- 接口隔离原则(Interface Segregation Principle):客户端不应该被迫依赖于它们不使用的方法。即一个类对另一个类的依赖应该建立在最小接口上。
- 依赖倒置原则(Dependency Inversion Principle):高层模块不应该依赖于低层模块,二者都应该依赖于抽象。抽象不应该依赖于细节,细节应该依赖于抽象。
数据类型
- 整型的默认类型是int
| |
- 浮点数的默认类型是double
二进制浮点数通过IEEE 754标准表示,float是4字节单精度32位;double是8字节双精度64位。
float符号位1位,指数位10位,尾数位21位;double符号位1位,指数位11位,尾数位52位。
| |
BigDecimal类可以表示任意精度的浮点数,避免精度丢失问题。
原理:使用整数进行计算,并通过scale属性记录小数点位置。
| |
表达式类型转换
最终结果由表达式的最高类型决定; byte、short、char在表达式中运算时直接提升为int参与运算。
运算符
+号在字符串运算中起连接作用,“abc”+5得"abc5",“abc”+5+‘a’得"abc5a", ‘a’+5+“abc"得"102abc”
| |
扩展赋值运算符:+=等五种 a += b 在编译器中是 a = (a的类型) (a + b)
短路与、或(&&、||):若左边为false/true,则不执行右边(如++b>1不会导致自加)提前返回结果。
方法中可变参数
方法签名中定义的特殊的形参,在类型后加上…,表示该形参可以接受任意数量的实参。
一个方法中的形参列表中,只能有一个可变参数,并且需要放在最后。
| |
StringBuilder
可变字符串,效率高于String。
| 方法 | 说明 |
|---|---|
StringBuilder append(任意类型) | 在字符串末尾追加内容 |
StringBuilder reverse() | 反转字符串 |
StringBuilder insert(int offset, String str) | 在指定位置插入内容 |
StringBuilder delete(int start, int end) | 删除指定范围的内容 |
返回值均为StringBuilder对象本身,因此可以链式调用。
示例:
| |
流程控制语句
switch
表达式支持数据类型:byte、short、char、int、String、枚举类型;不支持double、float、long (因为储存小数靠二进制拟合,0.3实际上是0.300..004之类,导致无法正确匹配)
case的值必须是确定的字面量,且不能重复 break关键字是可选的,如果没有则执行下一个case(穿透性,当几种case处理代码一致时可以复用);如果有,则跳出switch语句。 default也是可选的。
注解
注解是代码中的一种元数据,用于为程序元素(类、方法、变量等)提供额外的信息。本质是一种特殊的接口。
元注解
元注解是用于注解的注解,主要有以下几种:
- @Retention:定义生命周期-源码/类文件/运行时
- @Target:定义适用范围-类/方法/变量等
- @Documented:将注解包含在Javadoc中
- @Inherited:允许子类继承父类的注解
自定义注解
使用 @interface 关键字定义注解。
| |
注解的解析
使用反射机制获取注解信息,并根据注解执行相应的逻辑。
getDeclaredAnnotations():获取当前对象上所有注解
getAnnotation(Class
导第三方包
使用import语句导入第三方包中的类或接口,以便在代码中使用。
语法:
| |
在项目中创建lib文件夹,放入jar包,然后在jar包上右键选择“Add as Library”。
面向对象
三大特征:封装、继承、多态
构造器
创建类的对象时,会自动调用构造器(不指定即是默认的无参)。
是一种特殊的方法(因此可以重载),无返回值类型,且名称必须和类名相同。
类中默认自带无参构造器,但一旦定义了有参构造器,就不能使用默认无参构造器(需要自行手动构建的无参)。
| |
this关键字
this是方法中的一个变量,用于指代调用方法的对象。
解决变量名称冲突问题:如方法的局部变量名/形参名和类成员变量名冲突,用this访问类的变量可以避免冲突,使得可以使用相同的名称。
| |
静态方法不可能出现this关键字。
封装
设计要求:合理隐藏、合理暴露
隐藏
使用private关键字修饰成员变量,使得只能在本类中被直接访问。
暴露
使用public关键字修饰方法,通过方法操作成员变量。
在方法中可以添加限制,限定成员变量的范围等。
好处:如果需要修改变量类型,只需修改类中对应的方法,不用修改每一个调用的地方。
实体类
成员变量全部私有,并提供公开的getter、setter方法;需要提供无参构造器(有参可选)。 只用于保存事物的数据而不进行处理。
继承
public class B extends A{}//B是子类,A是父类
子类能继承父类的非私有成员(变量、方法)
子类的对象由父类和子类共同构建:
父类的private成员也在子类对象里,只是子类代码不能直接访问,要靠父类提供的public/protected方法间接访问。
提高代码复用性:可以使用父类的public属性和方法(父类方法可以重写),也可以有自己新的属性和方法满足拓展。
继承的特点
1.java不支持多继承(因为多个父类的方法可能冲突),但可以使用多层继承 2.java的祖宗类:object 3.子类访问成员遵循就近原则
| |
子类构造器
子类的构造器必须先调用父类的构造器,再调用自己的。
1.默认调用父类的无参super(),可以用super(…)调用父类的有参。
2.可以使用this(…)调用子类的构造器
| |
final关键字
可以修饰类、方法、变量。
- 修饰类:称为最终类,不能再被继承;
- 修饰方法:称为最终方法,不能被重写;
- 修饰变量:该变量除了初始化时,不能被赋值。 对于引用变量(数组):其地址(指向的对象)不可改变,但其指向对象的内容值可以改变
常量名采用全大写,单词间以下划线分割。
多态
- 定义与表现 多态是指在继承或实现关系下,同一个行为具有不同的表现形式。
- 对象多态:父类类型的变量可以指向不同的子类对象(
Animal a = new Dog();)。 - 行为多态:同一方法调用,根据实际对象类型的不同而执行不同的逻辑(子类重写的方法)。
前提条件
继承/实现:存在父子类继承关系或接口实现关系。
方法重写:子类必须重写父类的方法。
向上转型:父类类型的变量引用子类对象。
核心识别规律(重点) 在多态形式下,程序遵循以下原则:
- 成员方法:编译看左,运行看右。
- 编译时,父类必须定义该方法,否则报错。
- 运行时,实际执行的是子类重写后的逻辑。
- 成员变量:编译看左,运行看左。
- Java 的成员变量没有多态性,获取的是声明类型(父类)中的值。
- 局限性:多态对象无法直接调用子类独有的方法(若需调用,需进行向下转型)。
- 优势与意义
- 解耦性:隐藏了具体的子类实现,使代码更加通用。
- 可扩展性:符合“开闭原则”,新增业务子类时,原有的父类引用代码无需修改。
| |
反射
作用:
- 1.在运行时动态获取类的信息(类名、方法、属性等),并可以动态创建对象、调用方法和访问属性(可以通过setAccessible(true)访问私有属性)。
- 2.可以绕过泛型(因为类型擦除)进行操作。
- 3.适合用于通用框架开发,如Spring、Hibernate等。
| |
特殊类
单例类(单例设计模式)
构造器私有化,以在类内创建唯一的对象,确保某个类只能创建一个对象(应用如任务管理器)。
| |
枚举类enum
用于信息分类和标识,常应用于switch的case处
| |
1.枚举都是继承自Enum的最终类,不可被继承;
2.枚举类的第一行只能罗列常量的名称,每个常量都是枚举类的一个对象;
3.枚举类的构造器私有,因此不会对外创建对象
抽象类abstract–模板
使用abstract关键字修饰类和方法。
抽象方法没有方法体,只有方法声明。
如public abstract void m();
1.抽象类中可以没有抽象方法,但抽象方法必须在抽象类中。 2.抽象类不能创建对象,仅作为父类以供继承。 3.抽象类的子类必须重写抽象类的全部抽象方法。
因此抽象类强迫子类重新实现抽象方法,避免方法不适用。常用于多态
接口interface–功能
定义规范,分化出不同实现类,使得可以在不同实现类中灵活切换。
使用 implements(实现)关键字 通过接口实现“多继承”,注意要重写所有接口的抽象方法。
// class C implements A , B {//重写全部抽象方法}
规则
接口中只允许定义常量(默认加public static final,因此实际为常量)
接口中允许定义抽象方法
接口中允许定义特定实例方法(Java 8 之后)
接口不能创建对象(无构造器、只有抽象方法)
接口也可以用于多态(相当于义父,地位低于父类)
JDK8后新增三种实例方法
增强了接口的功能,且添加功能时避免已有的实现类需要重写。
1.默认方法
使用default修饰,默认会被加上public。
只能由接口的实现类对象调用。
2.私有方法
使用private修饰
只能被接口中其它实例方法调用。
3.静态方法
使用static修饰,默认会被加上public。
只能由接口名调用。
*接口与继承的注意事项
1、接口可以多继承,且同名方法会合并;
2、若多个接口出现方法签名冲突,则不支持多继承,也无法被实现;
| |
3、一个类继承了父类,同时又实现了接口,若父类和接口中有同名方法,遵循“类优先原则”,会优先调用父类中的同名方法;
4、可以通过重写冲突方法来规避2中的报错。
如果一定要调用3 4中接口的方法,使用 接口名.super.方法名 进行调用。
代码块
分为两种:
静态代码块: static{…}
类加载时自动执行,只会执行一次(类只加载一次),常用于静态变量初始化。
实例代码块: {…} 创建对象时自动执行,常用于对实例变量初始化。
内部类
定义在另一个类内部的类。
1.成员内部类
成员内部类寄生于 外部类的对象。
成员内部类可以直接访问外部类的所有成员属性。
| |
2.静态内部类
由static关键字修饰,只在创建时加载一次,不允许访问外部类中 非static 的变量和方法(即外部类对象)。
Outer.Inner a = new Outer.Inner();
3.局部内部类
局部内部类是定义在一个方法或者一个作用域里面的类,其生命周期仅限于作用域内。 不能被权限修饰符(public、private、protected、static)修饰
4.匿名内部类(子类对象)
在创建对象的同时,当场声明并实例化的一个类。用于创建只需要使用一次的、临时的实现类。
主要是用来继承其他类或者实现接口,并不需要增加额外的方法,方便对继承的方法进行实现或者重写。
唯一一种没有构造方法的类,是直接通过new关键字创建的一个子类对象。既是类也是对象。
格式:
| |
| |
函数式编程
Lambda表达式
用于替代**函数式接口(有且仅有一个抽象方法)**的匿名内部类对象。
用注解 @FunctionalInterface 来声明函数式接口。
格式:
(被重写方法的形参列表) -> {被重写方法的方法体}
Lambda语句简化规则:
参数类型可以省略不写;单个参数可以省略();只有单行代码时,可以省略{},同时需要去掉分号和return(如果是return语句的话)
方法引用
1.静态方法引用
用法:当Lambda表达式调用了一个静态方法时,且->前后参数形式一致。
格式:类名::静态方法名
| |
2.实例方法引用
用法:当Lambda表达式调用了一个实例方法时,且->前后参数形式一致。
格式:对象名::实例方法名
3.特定类的方法引用
用法:当Lambda表达式调用了一个实例方法时,且第一个参数是方法的主调,后续参数均为该方法的参数。
格式:特定类名::方法名
| |
4.构造器引用
用法:当Lambda表达式只是在创建对象,且->前后参数形式一致。
格式:类名::new
| |
API
String
1.通过new创建新对象
提供了四种构造器API:可创建空字符串,根据字符串、字符数组、byte数组创建。
| |
与常规初始化(String s = ‘hello’)不同的地方:
常规方法的字符串对象存储在字符串常量池,相同内容的对象s1 s2实际是同一个对象;
而new方式会创建新的对象(即使对象内容相同)放在堆内存中
2.部分常用API
获取index处的字符: charAt(int index); 将字符串转换为字符数组char[]: toCharArray();
忽略大小写比较: equalsIgnoreCase(); 截取: substring(bIndex, eIndex); 替换: replace(target, replacement);
泛型
在编译阶段约束数据类型,保证数据类型一致性,避免强制转换异常。
泛型只在编译时起作用,运行时并不会保留泛型类型信息。
| |
可以用各字母指代泛型,常用<E/T/K/V>,意义分别是Element/Type/Key/Value,
包装类
泛型只支持对象类型,不支持基本数据类型。
因为类型擦除后泛型容器在底层实际上按照一个 Object[] 数组来存储元素,而基本数据类型不属于object的子类。
于是使用包装类Integer、Character(其余均是首字母大写),它们是基本数据类型的对象版本,并且可以直接当基本类型使用(自动装拆箱)。
| |
| |
类型擦除
JVM编译时会把泛型的 类型变量 擦除,并替换为限定类型(没有限定则是Object),这会导致一些问题
下例类型变量String和Date在擦除后会自动消失,method方法的实际参数是ArrayList list,因此导致编译失败
| |
泛型类/接口/方法
泛型类
| |
泛型接口/方法:可以在实现时才指定具体类型,使得接口/方法更通用。
| |
泛型限定符extends
限定符 extends 可以缩小泛型的类型范围
| |
通配符
**通配符**用来解决类型不确定的情况,例如在方法参数或返回值中使用。
**上限通配符<? extends T>**表示通配符只能接受 T 或 T的子类。
**下限通配符<? super T>**表示通配符必须是 T 或 T的超类。
| |
假设有一个类Animal及其子类 Dog和Cat。则对于List<? super Dog>集合,类型参数必须是Dog或其父类类型。
可以向该集合中添加Dog类型的元素,也可以添加它的子类元素。但是不能向其中添加Cat类型的元素。
PECS (Producer Extends, Consumer Super)原则
? extends T:可以安全地读取数据,但限制了写入。
? super T:可以安全地写入数据,但限制了读取。
集合框架(容器)
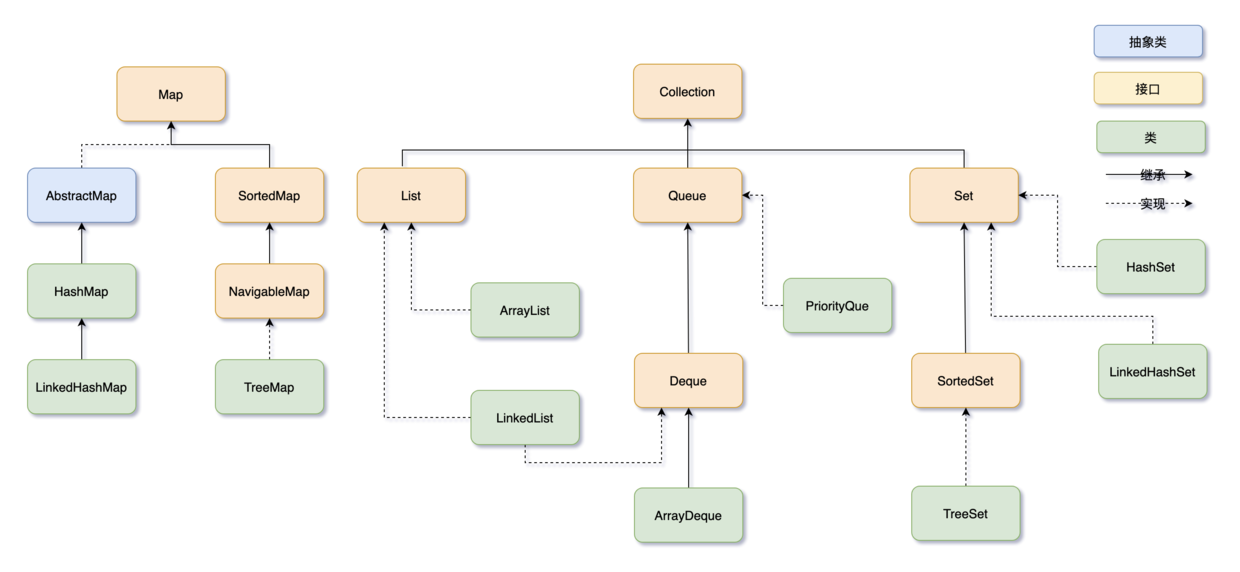
Collection
常用方法
| 方法 | 说明 |
|---|---|
| public boolean add(E e) | 把给定的对象添加到当前集合中 |
| public void clear() | 清空集合中所有的元素 |
| public boolean remove(E e) | 把给定的对象在当前集合中删除 |
| public boolean contains(Object obj) | 判断当前集合中是否包含给定的对象 |
| public boolean isEmpty() | 判断当前集合是否为空 |
| public int size() | 返回集合中元素的个数。 |
| public Object[] toArray() | 把集合中的元素,存储到数组中 |
遍历方法
1.普通for循环
只适用于有索引集合。
2.迭代器
| |
3.增强for循环(for-each) 本质是迭代器遍历集合的简化写法。
格式:for(元素数据类型 变量名 : 要遍历的数组/集合)
| |
4.forEach方法
源码:
| |
调用:
| |
并发修改异常
对于有索引的集合,在一次遍历中使用list.remove(),后续的元素位置会前移,而迭代器的游标位置后移,导致跳过了一个元素。
1 在for循环中删除元素时进行i–,或者从后往前进行循环
2 迭代器会检测是否出现并发修改异常并报错,使用迭代器的it.remove()可以避免,对于无索引的集合只能使用迭代器
3 增强for和forEach方法无法解决并发修改异常,只适合用于遍历
List
均有序、可重复、有索引,因此多了与索引相关的方法。
有ArrayList、LinkedList两种实现类。其底层数据结构分别是动态数组和双向链表,应用场景不同(查询/增删)。
· ArrayList第一次添加元素时,默认容量为10,后续每次扩容为原来的1.5倍。
· LinkedList可以从头尾两端添加元素,多了与头尾相关的方法。常用于构建队列、栈等。
Set
所有set都不重复、无索引;set本身无序。
特点:
有HashSet、LinkedHashSet、TreeSet三种实现类,其增删查改的速度均快。
HashSet底层是哈希表,无序。
LinkedHashSet底层是哈希表+链表,有序(默认插入顺序)。
TreeSet底层是红黑树,有序(默认升序排序)。
HashSet
基于哈希表实现,依赖于元素的 hashCode() 和 equals() 方法(其底层几乎完全复用了 HashMap,元素作为 Key 存入,Value 统一为固定的 PRESENT 对象)。
如果希望 HashSet 认为内容相同的对象是一样的,则必须重写这两个方法。
哈希表核心流程(JDK 8+)
- 初始化:首次添加元素时,默认创建长度为 16 的数组(哈希数组),默认加载因子为 0.75。
- 寻址定位:添加元素时,首先计算对象
hashCode()对应的哈希值,结合数组长度通过位运算确定该元素在数组中的索引槽位(即“桶”的位置)。 - 处理冲突:
- 若该槽位为空,直接在此创建新节点。
- 若该槽位已有其他元素(发生哈希冲突),则沿着链表依次调用
equals()方法进行比较。 - 若发现
equals()结果为 true(有重复元素),则放弃插入;若全不相同,则将该新元素添加到该槽位的链表末尾(尾插法)。
扩容与树化机制:
- 数组扩容:当哈希表中的元素总个数超过阈值(初始为 $16 \times 0.75 = 12$)时,数组容量会扩容为原来的 2 倍,并重新计算各节点的位置(Rehash)。
- 转红黑树:当某个槽位中的链表长度超过 8 且 当前数组总长度大于等于 64 时,该处的链表会转换为红黑树,将查询的时间复杂度从 O(n) 降低至 O(log n)。(若链表大于 8 但数组小于 64,则优先进行数组扩容)。
哈希值 (Hash Code):
- Java 中每个对象都有
hashCode(),返回一个int整数。默认实现通常基于对象在内存中的地址计算。 - 特性要求:只要对象的内部属性未被修改,多次调用
hashCode()必须返回同一个值。 - 哈希冲突:不同对象的哈希值可能(且一定概率会)相同。哈希表就是为了解决这个问题才引入了链表/红黑树结构。
经典考点:为什么重写 equals() 时必须重写 hashCode()?
重写 equals 是为了保证逻辑正确性(业务层面)。 重写 hashCode 是为了保证数据结构的高效与合规(底层存储层面)。
- Java 官方契约:如果两个对象
equals比较相等,那么它们的hashCode值必须相等 - 哈希集合的定址规则: 先计算 hashCode 定位到哪个桶(定位)。 再在桶内用 equals 遍历比对(比对)。
- 定位失效带来的双重惩罚: 写入时: 无法正确识别“重复”,造成逻辑错误(Set中元素不唯一)。 读取时: 无法正确命中已存在的数据,造成功能失效(Map找不到值)。
| |
LinkedHashSet
继承自 HashSet。也是基于哈希表实现,但其底层通过 LinkedHashMap 提供支持。
核心差异:在原有哈希表(数组+链表/红黑树)的基础上,它额外为每一个节点增加了双向链表指针(before 和 after),用于记录元素的插入顺序。
它的查询、增删效率非常接近 HashSet,同时又保证了迭代输出的顺序与插入顺序完全一致。
TreeSet
基于红黑树实现,元素自动升序排序。
对于自定义类型,默认无法直接排序,需要重写compareTo()方法。重写方法可以保留相同值的元素。
Map
也叫做键值对集合,格式为:{key1:value1, key2:value2, …}。
其中key不可重复,value可以重复。key与value一一对应。
有HashMap、LinkedHashMap、TreeMap三种实现类。
其特点见上面set的三种实现类,因为实际上set系列集合底层是基于map实现的(只使用key丢弃了value)。
| |
常用方法
| 方法 | 说明 |
|---|---|
| public V put(K key, V value) | 添加元素,如果key已存在,则用新的value覆盖旧的value,并返回旧的value |
| public int size() | 获取集合的大小 |
| public void clear() | 清空集合 |
| public boolean isEmpty() | 判断集合是否为空, 为空返回true |
| public V get(Object key) | 根据键获取对应值 |
| public V remove(Object key) | 根据键删除整个元素 |
| public boolean containsKey(Object key) | 判断是否包含某个键 |
| public boolean containsValue(Object value) | 判断是否包含某个值 |
| public Set | 获取全部键的集合 |
| public Collection | 获取Map集合的全部值 |
遍历方式
1.键找值
先获取键的集合(keySet()方法),再通过键获取值(get(Object key)方法)
2.键值对
entrySet()方法获取键值对的集合,再通过getKey()、getValue()方法获取键和值。
| |
3.forEach方法
forEach方法可以遍历键值对,并对键值对进行操作。
| |
Stream流
用于对集合、数组进行操作的API,可以进行过滤、排序、映射、聚合等操作。
示例:
| |
获取stream流
- 集合的stream方法
| |
- 数组的stream方法
| |
- stream类的方法
| |
中间处理方法
调用完成后返回新的Stream流,可以链式调用。
| 方法 | 说明 |
|---|---|
| Stream | 过滤元素,返回符合条件的元素 |
| Stream | 对元素进行升序排序 |
| Stream | 按照指定规则排序 |
| Stream | 获取前几个元素 |
| Stream | 跳过前几个元素 |
| Stream | 去除流中重复的元素(自定义类的对象需要重写hashCode和equals方法) |
| 对元素进行加工,并返回对应的新流 | |
| static | 合并a和b两个流为一个流 |
终止方法
调用完成后返回结果,终止stream流。
| 方法 | 说明 |
|---|---|
| void forEach(Consumer action) | 对此流运算后的元素执行遍历 |
| long count() | 统计此流运算后的元素个数 |
| Optional | 获取此流运算后的最大值元素放入optional容器,避免空指针异常 |
| Optional | 获取此流运算后的最小值元素 |
| Object[] toArray() | 将流元素收集到数组 |
| R collect(Collector<? super T> collector) | 将流元素收集到容器中,collector类可以进一步收集到集合中 |
collect方法可以收集到集合中,如toList()、toSet()、toMap(keyMapper, valueMapper)等。 例:Map<String,Integer> map = stream.collect(Collectors.toMap(Students::getName, Students::getAge));// 收集到map集合
IO流
用于读取文件、网络中的数据。实际开发中常用框架如Apache Commons IO、Google Guava等来简化IO操作。
按内容分为:字节流(处理所有类型数据)和字符流(处理文本文件)。
按方向分为:输入流(从源读取数据)和输出流(向目的写入数据)。

文件类操作
| 方法 | 说明 |
|---|---|
| file.exists() | 判断文件是否存在 |
| file.isFile() | 判断是否为文件 |
| file.isDirectory() | 判断是否为目录 |
| file.getName() | 获取文件名 |
| file.length() | 获取文件大小 |
| file.lastModified() | 获取文件最后修改时间 |
| file.createNewFile() | 创建文件 |
| file.delete() | 删除文件或空文件夹 |
| file.mkdir() | 创建目录 |
| file.mkdirs() | 创建多级目录 |
| File[] listFiles() | 获取目录下所有一级文件对象到文件对象数组中 |
输入输出流
字节输入输出流
建立
| 类 | 说明 |
|---|---|
| InputStream in = new FileInputStream(file/path); | 建立字节输入流 |
| BufferedInputStream bin = new BufferedInputStream(in); | 缓冲字节输入流,提高读取效率 |
| OutputStream out = new FileOutputStream(file/path, boolean append); | 建立字节输出流,append为true时表示追加写入 |
| BufferedOutputStream bout = new BufferedOutputStream(out); | 缓冲字节输出流,提高写入效率 |
读写方法
| 读写方法 | 说明 |
|---|---|
| int read(int b) | 读取一个字节 |
| int read(byte[] b [, int offset, int len]) | 从offset开始读取len个字节到byte数组b中 |
| byte[] ReadAllBytes | 读取整个文件内容到字节数组中 |
| write(int b) | 写出一个字节 |
| write(byte[] b [, int pos, int len]) | 写出字节数组 |
| close() throws IOException | 关闭流 |
资源释放方案
- try-catch-finally
| |
- try-with-resources(推荐)
在try后面的小括号内创建流对象,JVM会自动释放资源,避免忘记关闭流。
资源对象必须实现AutoCloseable接口(所有流类均已实现)。
| |
字符输入输出流
建立
| 类 | 说明 |
|---|---|
| FileReader fr = new FileReader(file/path); | 建立字符输入流 |
| BufferedReader br = new BufferedReader(fr); | 缓冲字符输入流,提高读取效率 |
| FileWriter fw = new FileWriter(file/path, boolean append); | 建立字符输出流 |
| BufferedWriter bw = new BufferedWriter(fw); | 缓冲字符输出流,提高写入效率 |
| 读写方法 | 说明 |
|---|---|
| int read() | 读取一个字符 |
| int read(char[] cbuf [, int offset, int len]) | 从offset开始读取len个字符到char数组cbuf中 |
| char[] ReadAllChars | 读取整个文件内容到字符数组中 |
| String readLine() | 缓冲流独有的功能:读取一行文本 |
| void write(int c) | 写出一个字符 |
| void write(String str [, int pos, int len]) | 写出字符串 |
| void write(char[] cbuf [, int pos, int len]) | 写出字符数组 |
| void newLine() | 缓冲流独有的功能:写出一个换行符 |
字符输出流写出数据后,需要调用 flush() 或 close() 方法将缓冲区数据强制写出,否则数据可能在内存中未写入硬盘文件。
字符输入/输出转换流
用于解决字节流与字符流之间的转换问题,指定编码格式。
| 类 | 说明 |
|---|---|
| InputStreamReader isr = new InputStreamReader(InputStream in, String charsetName); | 字节输入流转换为字符输入流,可指定编码格式 |
| OutputStreamWriter osw = new OutputStreamWriter(OutputStream out, String charsetName); | 字节输出流转换为字符输出流,可指定编码格式 |
打印流
更高效的输出流,提供了多种重载的print()和println()方法,可以直接输出各种数据类型。
| 类 | 说明 |
|---|---|
| PrintStream ps = new PrintStream(OutputStream/File/Path out, boolean autoFlush, String charsetName); | 字节打印流 |
| PrintWriter pw = new PrintWriter(Writer out, boolean autoFlush); | 字符打印 |
特殊流
数据流(Data Stream):用于读写基本数据类型和字符串,提供了readInt()、writeInt()等方法。 对象流(Object Stream):用于读写Java对象,提供了readObject()、writeObject()方法。对象必须实现Serializable接口。
| 类 | 说明 |
|---|---|
| DataInputStream dis = new DataInputStream(InputStream in); | 字节数据输入流 |
| DataOutputStream dos = new DataOutputStream(OutputStream out); | 字节数据输出流 |
| ObjectInputStream ois = new ObjectInputStream(InputStream in); | 字节对象输入流 |
| ObjectOutputStream oos = new ObjectOutputStream(OutputStream out); | 字节对象输出流 |
异常
有错误则抛出异常,但不会终止程序。
异常分类
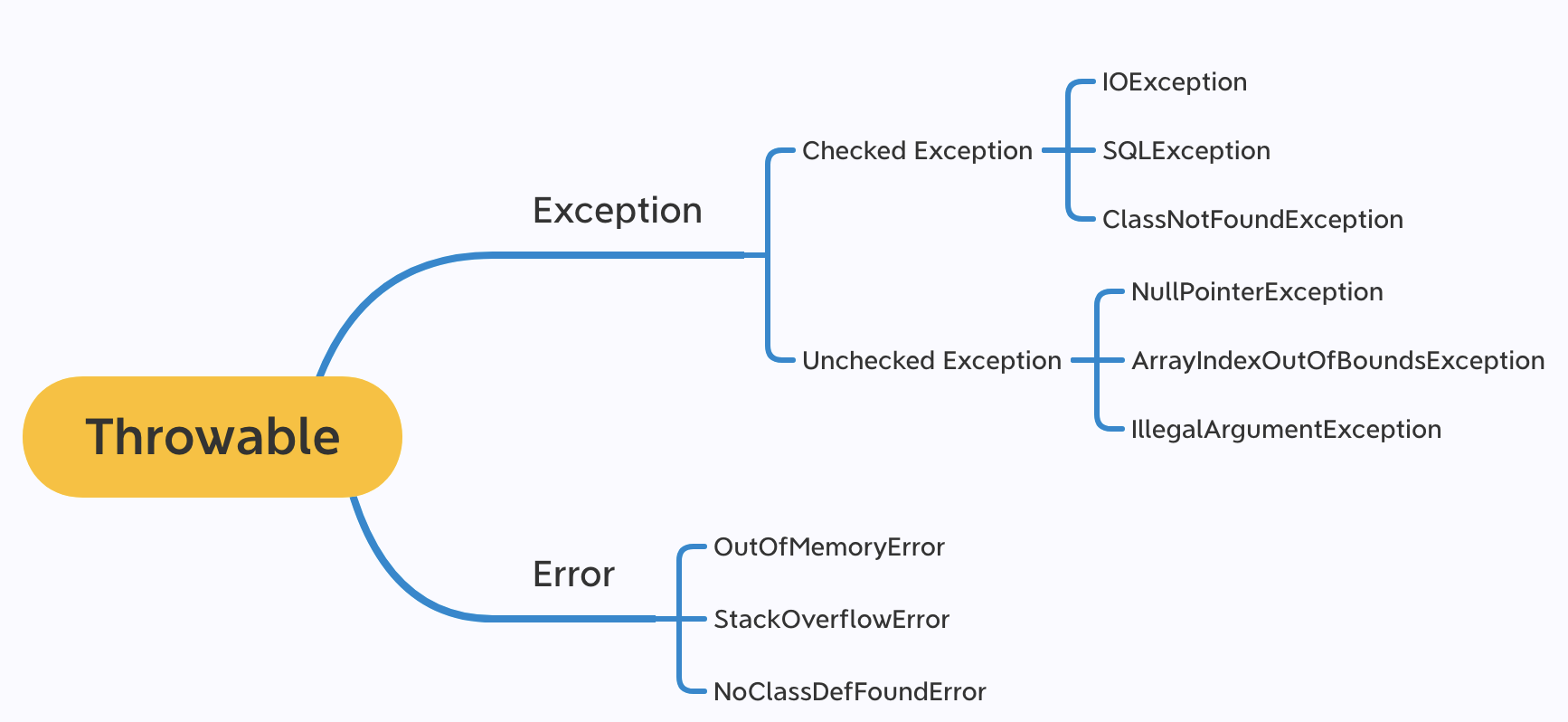 Exception和Error都继承了Throwable类。只有Throwable类(或者子类)的对象才能使用throw关键字抛出,或者作为catch的参数类型。
Exception和Error都继承了Throwable类。只有Throwable类(或者子类)的对象才能使用throw关键字抛出,或者作为catch的参数类型。
Checked Exception(受检异常):在编译期被检查的异常,必须显式处理(通过try-catch 或 throws)。正逐步淘汰。 Unchecked Exception(非受检异常 / 运行时异常):运行时异常,不需要在编译期显式处理。继承自:RuntimeException
·NoClassDefFoundError 和 ClassNotFoundException的区别:
都由于系统运行时找不到要加载的类导致,但触发原因不同。
NoClassDefFoundError:程序在编译时可以找到所依赖的类,但是在运行时找不到指定的类文件;原因可能是编译的类文件被删除。
ClassNotFoundException:当动态加载 Class 对象的时候找不到对应的类时抛出该异常;原因可能是要加载的类不存在或者类名写错了。
异常处理
try-catch(-finally)
| |
多个catch块捕获异常时,子类异常必须在前,父类异常在后,否则会报错。如ArithmeticException是Exception的子类,其范围更具体,因此要放在前面。
即便是try块中执行了return、break、continue这些跳转语句,finally块也会被执行。
不执行的情况:死循环 、JVM退出(System.exit(0))等。
throws和throw
throws关键字用于声明异常,它的作用和try-catch相似;而throw关键字用于显式的抛出异常。
throws关键字后面跟的是异常的名字;而throw关键字后面跟的是异常的对象。
| |
自定义异常
1.继承Exception或RuntimeException类 2.提供两个构造器:无参和带String参数(异常信息)
| |
JUnit
测试方法必须使用@Test注解标记,且方法必须是public无参无返回值。
| |
- 其他注解
注解 说明 @ParameterizedTest 参数化测试,可以使用不同的参数多次运行同一个测试方法 @ValueSource 为参数化测试提供值,与@ParameterizedTest一起使用 @BeforeAll 在所有测试方法执行前运行一次,必须是静态方法 @AfterAll 在所有测试方法执行后运行一次,必须是静态方法 @BeforeEach 在每个测试方法执行前运行一次 @AfterEach 在每个测试方法执行后运行一次
参数化测试示例:
| |
多线程
创建线程
- 继承Thread类,重写run()方法
| |
编码简单,但Java单继承的缺点也限制了其使用。
执行结果不能直接返回(run方法返回值是void)。
- 实现Runnable接口,重写run()方法
| |
扩展性强,但需要多创建一个Runnable对象。
执行结果不能直接返回(run方法返回值是void)。
- Callable接口,重写call()方法 Callable接口可以有返回值,并且可以抛出异常。
| |
线程的常用方法
| 方法 | 说明 |
|---|---|
| start() | 启动线程 |
| run() | 线程执行的代码 |
| sleep(long millis) | 让当前线程睡眠指定毫秒数 |
| join() | 调用该方法的线程优先执行 |
| isAlive() | 判断线程是否存活 |
| setName(String name) | 设置线程名称 |
| getName() | 获取线程名称 |
| setPriority(int newPriority) | 设置线程优先级,范围1-10,默认5 |
| getPriority() | 获取线程优先级 |
| currentThread() | 获取当前线程对象 |
线程同步
多线程并发访问共享资源时,可能会出现数据不一致的问题。
为了解决这个问题,可以使用以下几种方式进行线程同步:
- 同步代码块:在访问共享资源的代码块上加上
synchronized关键字,表示该代码块是同步的,只有一个线程可以访问。
| |
- 同步方法:在方法上加上
synchronized关键字,表示该方法是同步的,只有一个线程可以访问。
| |
- Lock锁:使用
java.util.concurrent.locks.Lock接口及其实现类(如ReentrantLock)来实现更灵活的线程同步。
| |
线程池
线程池可以复用线程,避免频繁创建和销毁线程带来的开销,提高系统性能。
常用方法:
| 方法 | 说明 |
|---|---|
| execut(Runnable task) | 提交Runnable任务到线程池,无返回值 |
| Future | 提交Callable任务到线程池,返回Future对象 |
| shutdown() | 任务执行完毕后,关闭线程池 |
| List | 立即关闭线程池,尝试停止所有正在执行的任务,返回队列中未执行的任务 |
1.ThreadPoolExecutor类 是线程池ExecutorService的核心类,可以通过构造器创建线程池。
构造器有七个参数,含义为:
- corePoolSize:核心线程数,线程池中始终保持的线程数。
- maximumPoolSize:最大线程数,线程池中允许的最大线程数。
- keepAliveTime:线程空闲时间,超过这个时间的空闲线程会被终止。
- unit:时间单位,keepAliveTime的时间单位。
- workQueue:任务队列,用于存放待执行的任务。
- threadFactory:线程工厂,用于创建新线程。
- handler:拒绝策略,当任务队列满且线程数达到最大值时,如何处理新任务。
创建临时线程的时机:当核心线程全被占用且任务队列满,同时线程数未达到maximumPoolSize时。
拒绝任务的时机:当核心线程全被占用且任务队列满,同时线程数已达到maximumPoolSize时。
| |
2.Executors工具类 本质是对ThreadPoolExecutor的封装,简化线程池的创建。
工具类静态方法:
| 方法 | 说明 |
|---|---|
| newSingleThreadExecutor() | 创建单线程的线程池,出现异常会自动补充 |
| newFixedThreadPool(int nThreads) | 创建固定大小的线程池,若有线程出现异常结束,会自动补充新的线程 |
| newCachedThreadPool() | 创建可缓存的线程池,线程数随任务数增加,空闲一分钟回收 |
| newScheduledThreadPool(int corePoolSize) | 创建固定大小的线程池,可以延迟或定时执行任务 |
弊端:
- FixedThreadPool和SingleThreadExecutor允许请求的队列长度无限制,可能导致内存耗尽。
- CachedThreadPool和ScheduledThreadPool允许创建的线程数无限制,可能导致系统资源耗尽。
因此阿里禁用Executors创建线程池。
示例:
| |
网络编程
Java提供了丰富的网络编程API,主要包括以下几个方面:
- Socket编程:用于实现TCP/IP协议的网络通信,包括客户端和服务器端的Socket编程。
- UDP编程:用于实现基于UDP协议的网络通信,适用于对实时性要求较高的场景。
- HTTP编程:用于实现基于HTTP协议的网络通信,包括发送HTTP请求和处理HTTP响应。
- WebSocket编程:用于实现基于WebSocket协议的双向通信,适用于实时应用场景。
Socket编程(TCP)
Socket编程是Java网络编程的基础,主要包括以下几个类:
| 类 | 说明 |
|---|---|
| Socket | 客户端Socket类,用于连接服务器 |
| ServerSocket | 服务器Socket类,用于监听客户端连接 |
| InetAddress | 表示IP地址的类 |
| SocketException | Socket操作异常类 |
创建客户端Socket
| |
创建服务器端Socket
| |
如果要处理多个客户端连接,可以为每个连接的socket创建一个新的线程。
| |
B/S架构
B/S(Browser/Server)架构是基于浏览器和服务器的网络架构,常用于Web应用开发。
HTTP协议是B/S架构中最常用的协议,Java提供了HttpURLConnection类用于发送HTTP请求和处理HTTP响应。
UDP编程
UDP编程主要包括以下几个类:
| 类 | 说明 |
|---|---|
| DatagramSocket | UDP Socket类,用于发送和接收数据包 |
| DatagramPacket | 数据包类,用于封装发送和接收的数据 |
创建UDP客户端
| |
创建UDP服务器端
| |